Agent Timeline is available on Free, Pro, and Enterprise Honeycomb plans.
- Select Agent Timeline from the main navigation.
- Enter a conversation ID (if you have one) or browse from the list of recent conversations.
You can also select a gen_ai.conversation.id from a Query Results view to open that conversation in the Agent Timeline.
To see your conversations or multi-agent sessions in the Agent Timeline, make sure your instrumentation emits spans with GenAI attributes.
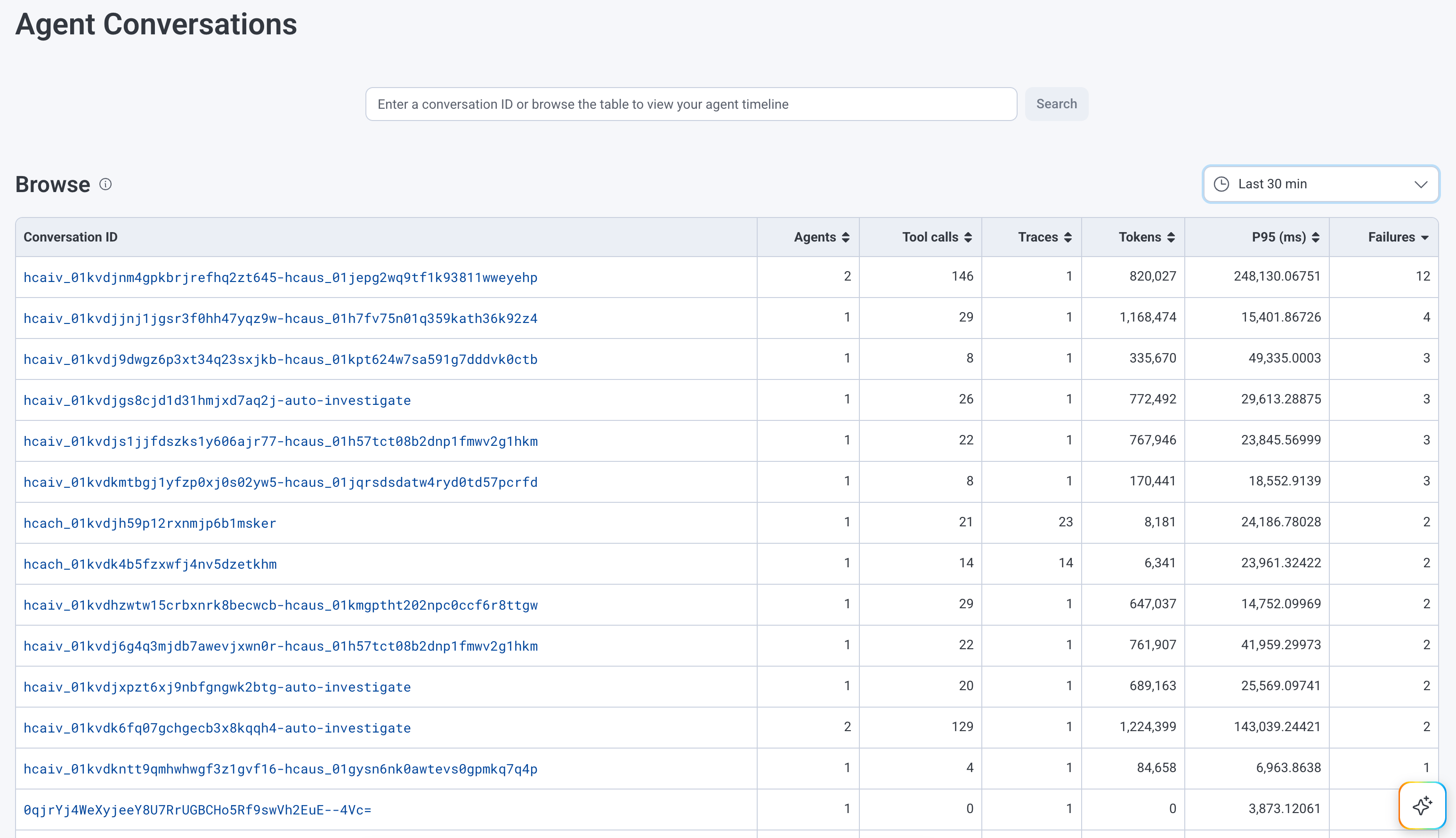
Conversations view
Browse from a list of agent conversations in the last 60 days.
Each entry in the list includes agent counts, tool calls, number of tokens, P95 latency, and failure counts.
Agent Timeline view
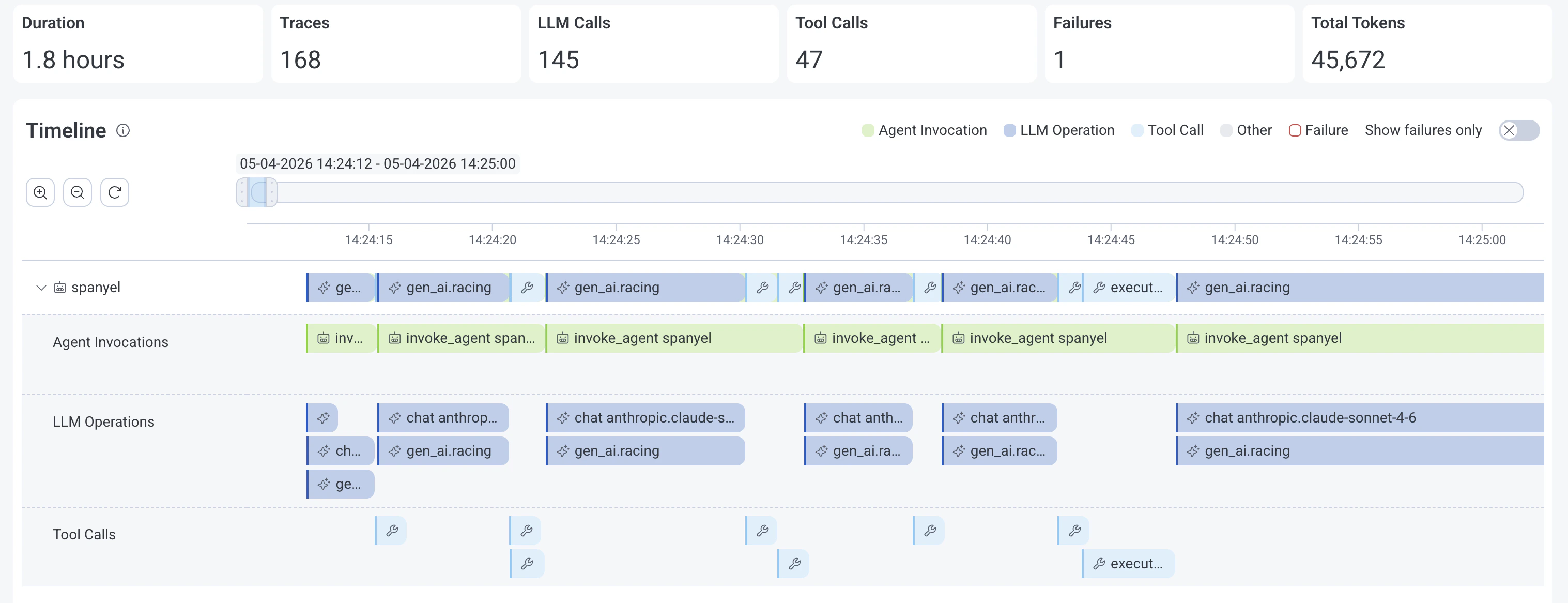
The conversation view of the Agent Timeline displays some key metrics at the top, a timeline of GenAI spans, a GenAI span details view on the side, and a traces view to inspect related spans and errors.
Conversation metrics:
- Duration: How long the conversation or session lasted.
- Traces: Count of traces.
- LLM Calls: Number of GenAI spans where the
gen_ai.operation.name attribute is equal to "chat", "generate_content", or "text_completion".
- Tool Calls: Count of GenAI spans where the
gen_ai.operation.name attribute is equal to "execute_tool".
- Failures: Error/exception count.
- Total Tokens: How many tokens were used, both input and output, in the conversation.
Conversation timeline
The conversation timeline displays GenAI spans grouped by agent name (gen_ai.agent.name), with nested GenAI spans grouped by GenAI operation type: Agent Invocations, LLM Operations, and Tool Calls.
Controls
- Move the slider to view different periods on the timeline.
- Zoom in/out (/) or resize the slider to adjust the viewable time period.
- Toggle Show Failures Only to only show spans with errors on the timeline.
- Expand or collaspe () an agent span group.
You can view spans nested under GenAI spans and related errors using the Traces view below the Timeline.
Selecting a GenAI span on the timeline opens a detailed view with three tabs: Gen AI, Fields, and Links.
In the Fields tab you can filter span fields by name or value, and if there any links on the span you can see them in the Links tab.
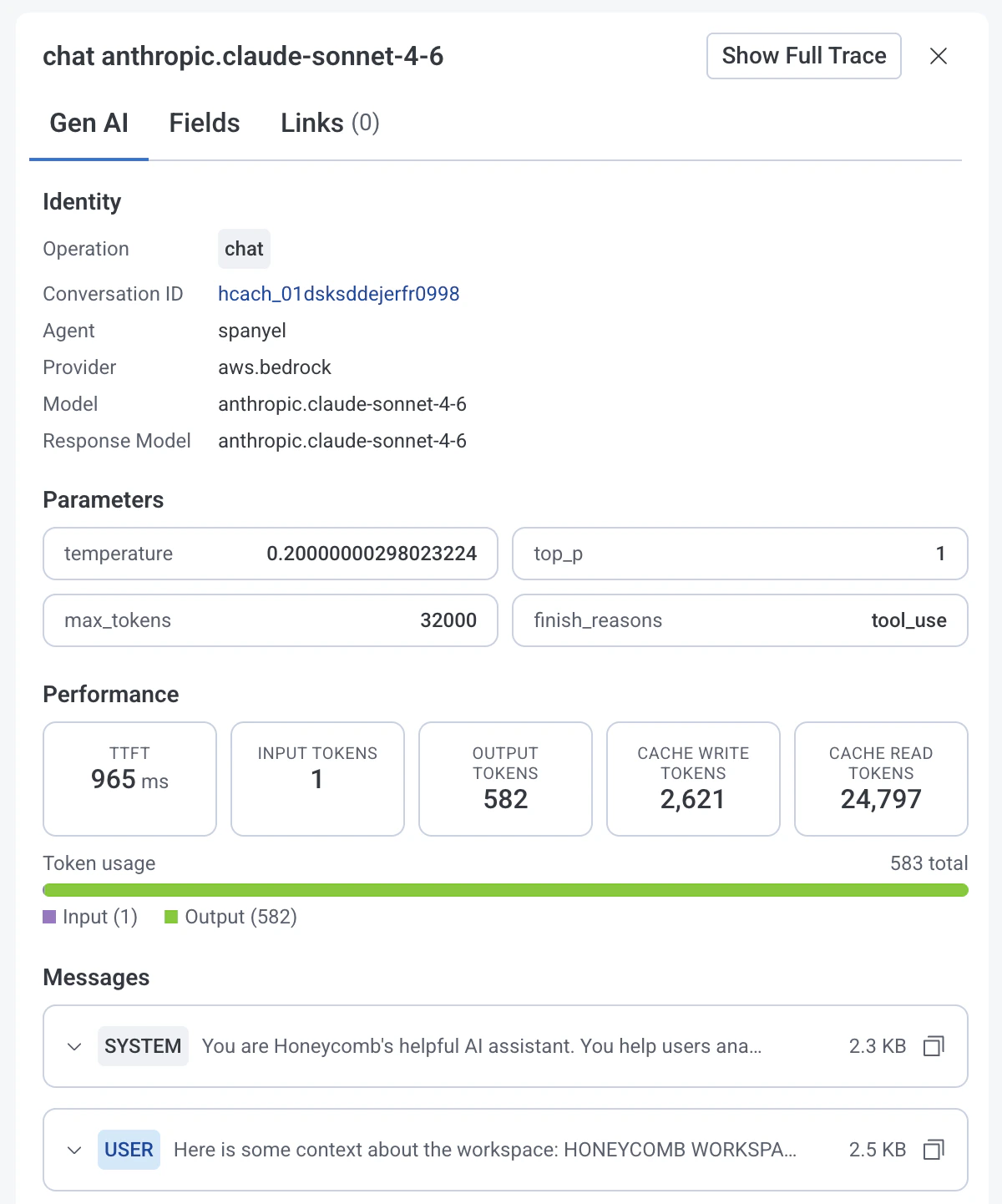
Gen AI tab
In the Gen AI tab you’ll find details about the selected GenAI span.
Identity
- Operation: The
gen_ai.operation.name (chat, invoke_agent, execute_tool)
- Conversation ID: Unique conversation identifier
- Agent: Name of the agent
The rest of the fields you see depend on the type of GenAI span you select.
Agent invocations
The Gen AI tab displays conversation content (if available) for agent invocation spans.
In the Messages section, you’ll see content of the conversation if available. This includes system and user prompts along with responses from LLMs and tools.
LLM operations
The Gen AI tab displays the following fields for LLM operation spans.
- Provider: Name of the LLM provider
- Model: Requested LLM model
- Response Model: LLM model that generated the response
Parameters
- Temperature: Requested temperature setting.
- Max Tokens: Requested maximum number of tokens the model should generate.
- Top P:
top_p sampling setting for the LLM request.
- Finish Reasons: Reasons why the LLM model stopped generating tokens.
Performance
- Time To First Token (TTFT): Time elapsed between sending a request to the LLM model and receiving the first token of its response.
- Input Tokens: Number of input tokens used.
- Output Tokens: Number of output tokens used.
- Cache Write Tokens: Count of tokens written to cache.
- Cache Read Rokens: Count of tokens read from cache.
- Token Usage: Total amount of tokens used by the operation.
In the Messages section, you’ll see content of the conversation if available. This includes system and user prompts along with responses from LLMs and tools.
The Gen AI tab displays the these fields for tool call spans.
- Tool Name: Name of the tool or function
- Type: Type of tool used by the agent (
function, extension, datastore)
- Call ID: Unique tool call identifier
Any arguments passed to the tool call are displayed (in JSON format), followed by the result (if any).