

This feature is available as an add-on for the Honeycomb Enterprise plan.
Please contact your Honeycomb account team for details.
How It Works
If you have configured an Amazon S3 bucket as an archive for OpenTelemetry trace and log data, you can rehydrate that data and query it in Honeycomb. This is useful for investigating data that was sampled out or data that has expired from your standard retention period.Filtering
Time ranges and indexed fields let you filter and retrieve only the part of your archived data needed for your investigation, resulting in faster rehydration and lower costs. Indexed fields are attributes configured when you set up your S3 exporter. When you rehydrate data from your archive, Honeycomb:- Reads your S3 bucket using the IAM role you configured during archive setup.
- Filters by time range and indexed fields to retrieve only files that contain events matching your criteria. For example, all files with events between
2024-01-15 10:00and2024-01-15 11:00whereapp.customer.id=12345. - Ingests the matching files into your S3 Archive environment for querying. Files that were already ingested from previous rehydration requests and are still within your retention period are skipped.
Rehydrated Data Persistence
Rehydrated data persists for your standard retention period from the time of ingestion. During this time, you can query it as many times as needed without rehydrating again. When you request a rehydration, Honeycomb checks which data has already been ingested. If some of the requested data already exists in your environment, only the missing data is ingested. Your queries then run against all the rehydrated data in your environment.Enhancing a Query with Archived Data
You can enhance an existing query by pulling in relevant archived data that matches your time range and indexed fields. To enhance a query with archived data from your S3 bucket:- Run a query in the Query Builder and receive your query results.
-
From the Query Results, select Enhance from Archive.
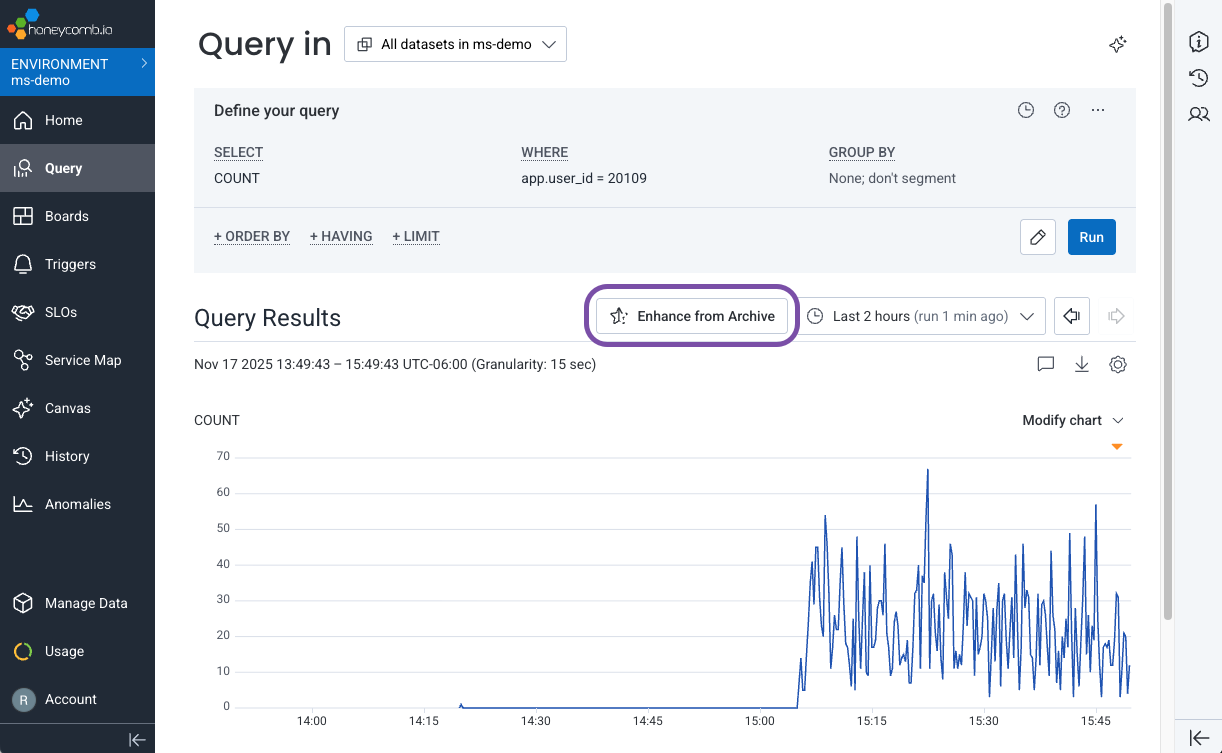
-
In the Enhance from Archive modal, define the scope of your rehydration:
-
Review your usage estimate to confirm:
- Approximate number of events based on the average size of previously rehydrated events
- Approximate number of free monthly rehydration events that will be used and free events remaining
- Approximate regular monthly events that will be used and regular events remaining
-
Select Rehydrate data to begin ingesting the archived data that matches your query and chosen rehydration scope.
You will be redirected to the History () page in your Amazon S3 Environment.
When ingestion completes, Honeycomb automatically re-runs your query using the rehydrated data.
A notification appears with a link to your query results.
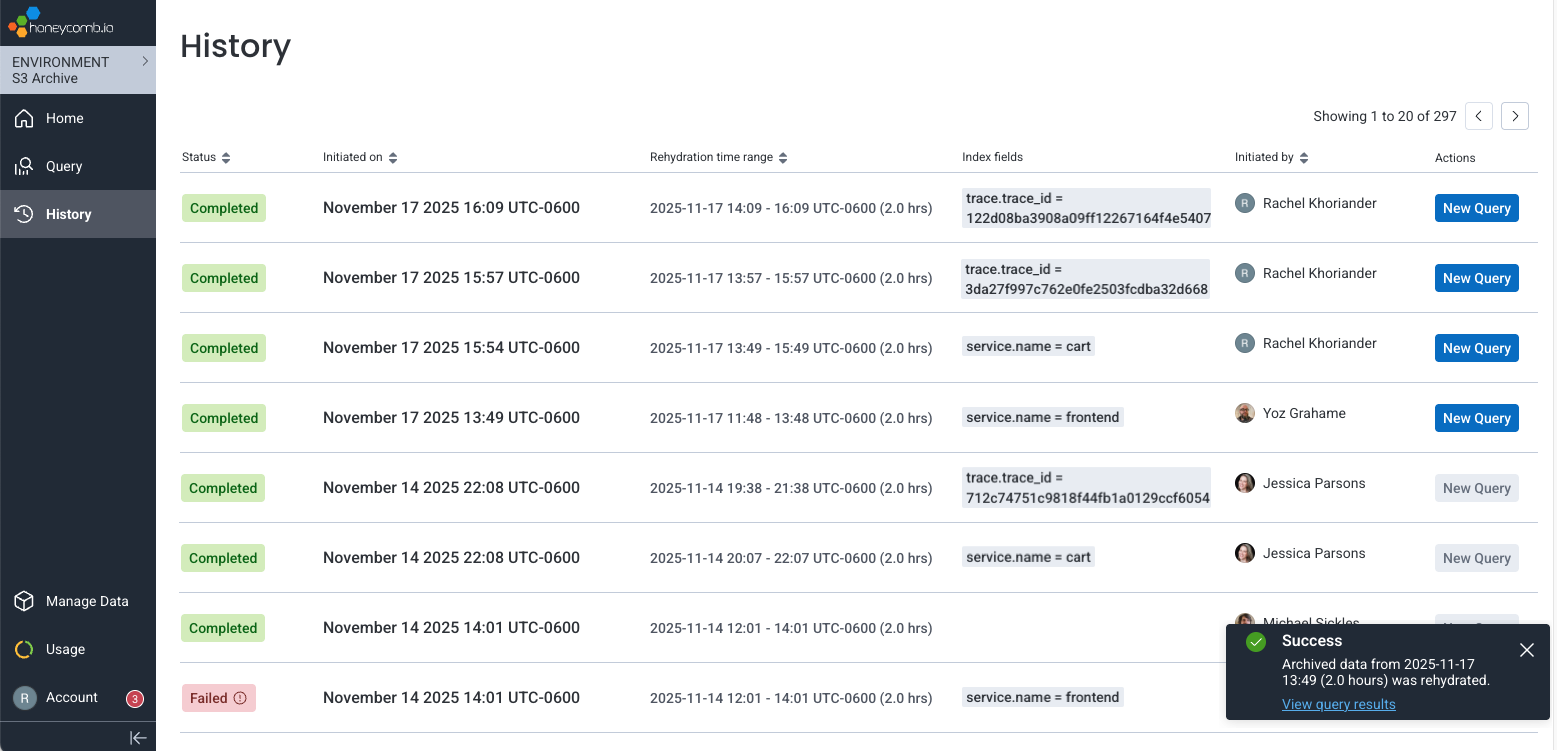
- Select the link in the notification to view your query with the rehydrated data.
Enhancing Traces with Missing Spans
When you rehydrate data using a filtered index (such ascustomer.id), your trace waterfall may show gaps where spans are missing.
This happens because not every span in a trace contains the indexed field you filtered by.
To retrieve the missing spans, rehydrate again using the trace ID:
-
From the Trace Waterfall view, select Enhance again.
To reach the Trace Waterfall: From your query results, select a data point on the graph and choose View Trace from the context menu.
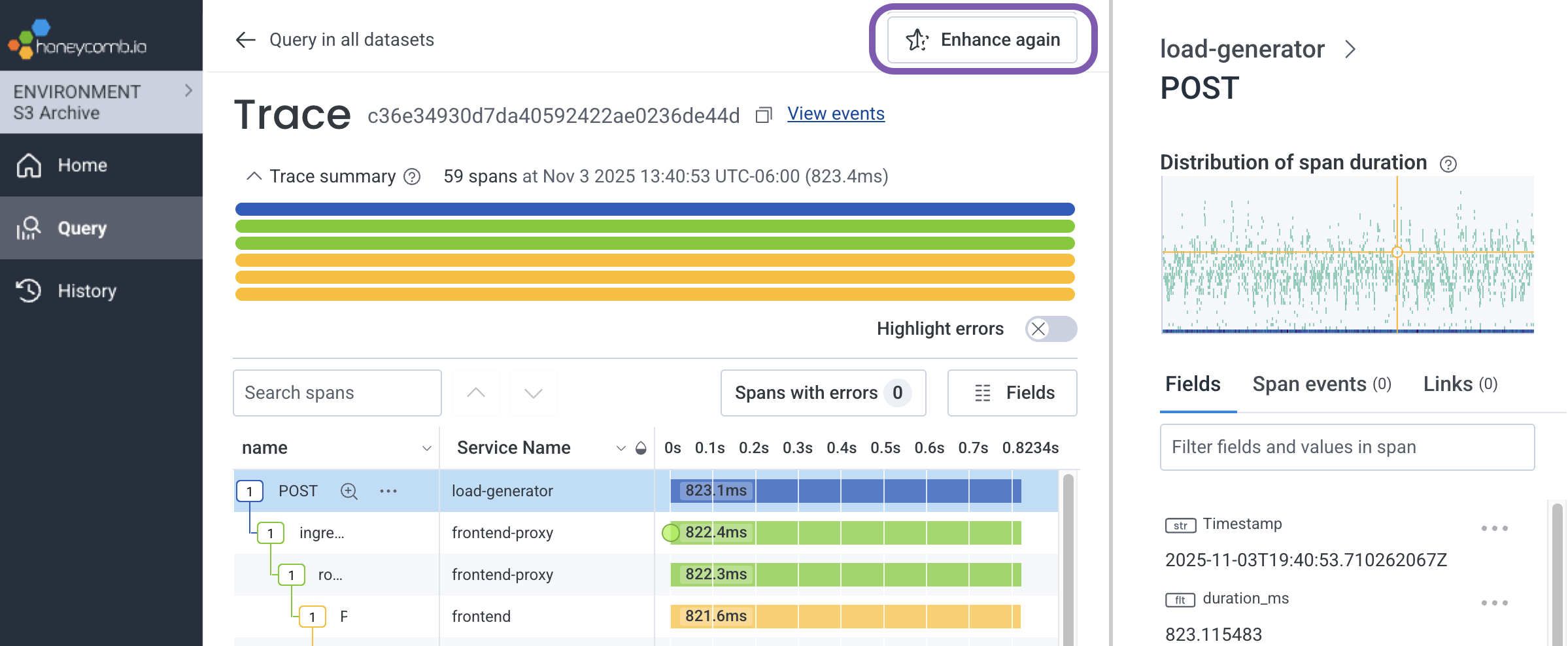
-
In the modal, review the automatically-populated scope of your rehydration:
-
Review your usage estimate to confirm:
- Approximate number of events based on the average size of previously rehydrated events
- Approximate number of free monthly rehydration events that will be used and free events remaining
- Approximate regular monthly events that will be used and regular events remaining
- Select Rehydrate data to ingest the missing spans. You will be redirected to the History () page in your Amazon S3 Environment.
Querying Only Archived Data
You can explore archived data independently from your live telemetry by rehydrating and querying it in your dedicated archive environment. To query only archived data from your S3 bucket:- Select Manage Data () from the navigation menu, and choose Environments.
- Select your S3 Archive Environment.
-
Define the scope of your rehydration:
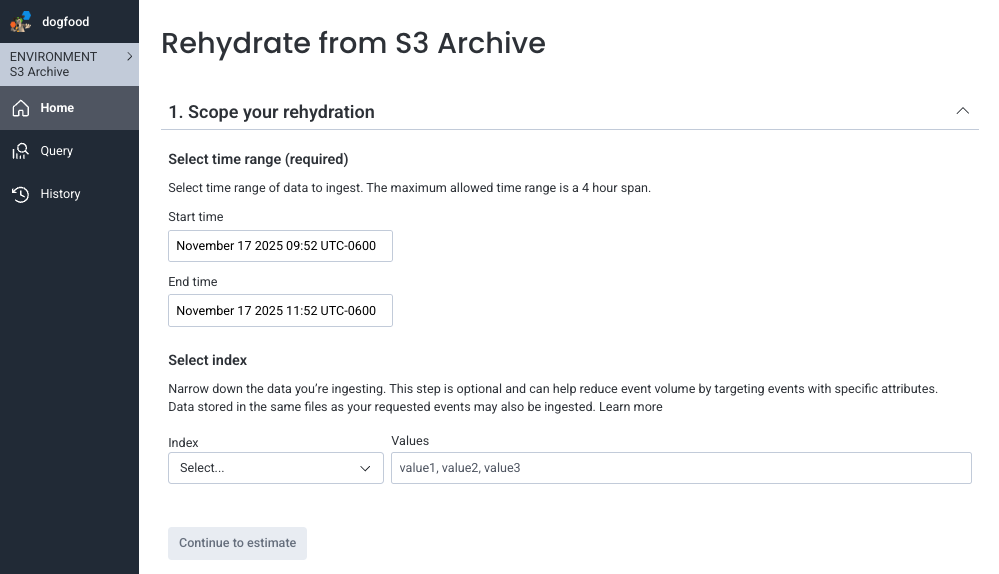
- Review your usage estimate and adjust your criteria to optimize cost and event count.
- Select Rehydrate data.
- After rehydration completes, select New Query to begin querying your ingested archived data.
- Honeycomb pre-populates the query with your chosen rehydration scope as filters. Add fields, filters, or visualizations to further refine your query.
Reviewing Rehydration History
You can review all rehydration requests for your team in your archive environment:- Select Manage Data () from the navigation menu, and choose Environments.
- Select your Amazon S3 Environment.
-
Select History () from the navigation menu.
For each rehydration request, the history shows:
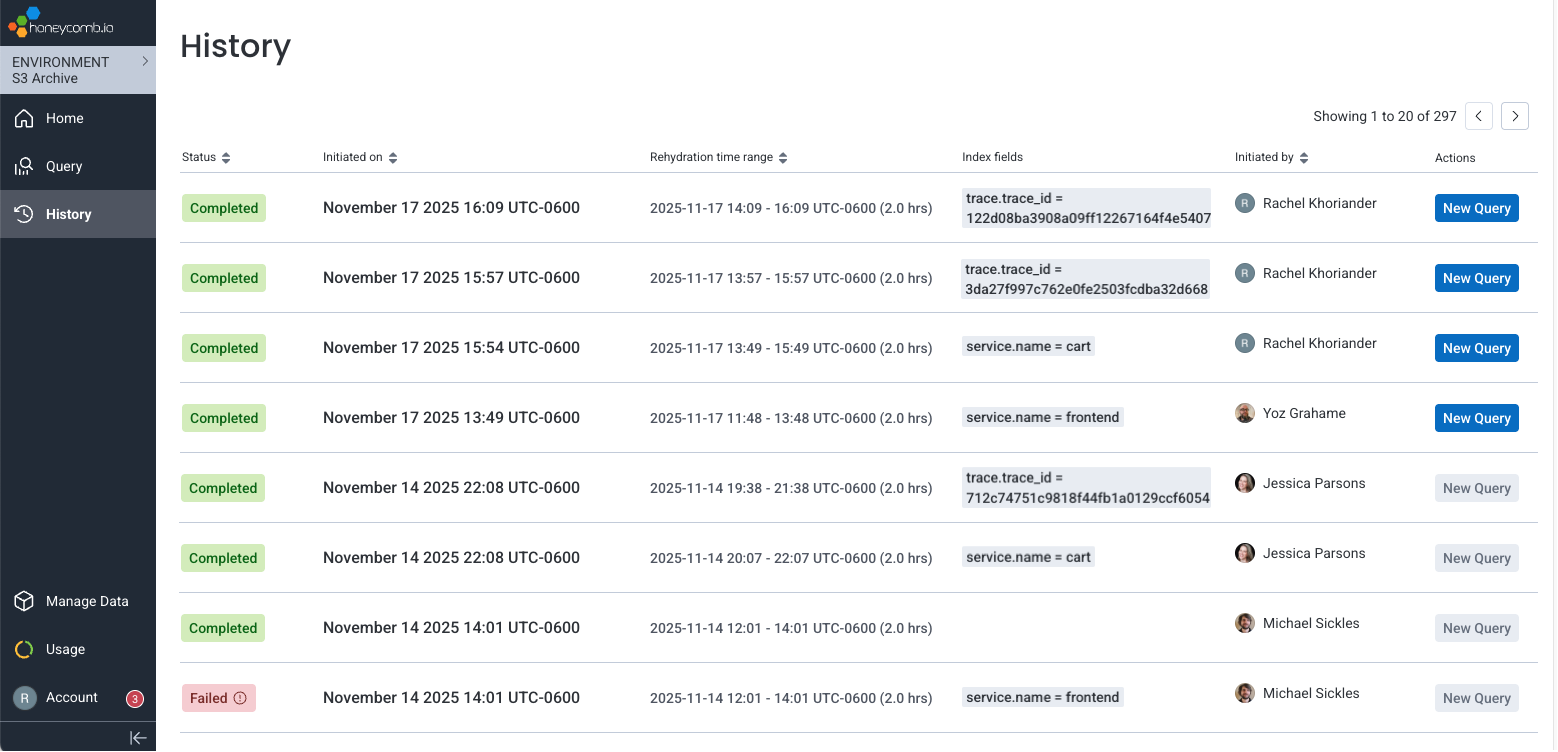
- Status: State of the rehydration request.
Possible states:
- Completed: Data was successfully rehydrated and is ready to query.
- No Data: No archived data matched your filter criteria. Verify that your S3 bucket contains data for the specified time range and index values.
- Failed: An error occurred during rehydration. Our team has been notified.
- Initiated date: Date and time at which the rehydration request was initiated.
- Rehydration time range: Time range filter applied to the rehydration.
- Index fields: Field-based indexes and values used to filter the rehydrated data.
- Initiated by: User who initiated the rehydration request.
- Actions: Available actions for this rehydration request:
- New Query: View the results of a completed rehydration request. The Query Builder opens, showing a query pre-populated with the rehydration filter criteria.
- Status: State of the rehydration request.
Possible states:
Best Practices for Rehydration
- Use specific indexed fields: Filter by high-cardinality fields like
user.idortrace.trace_idrather than low-cardinality fields likeenvironmentto reduce the number of events ingested. - Start with narrow time ranges: Begin with shorter time windows and expand as needed to control costs.
- Check the estimate: Always review the estimated event count before rehydrating to avoid unexpectedly large ingestion volumes.
- Don’t worry about tracking rehydrated data: Honeycomb automatically tracks which files have been ingested, so you can make overlapping rehydration requests without duplicating ingestion or costs. Once data is rehydrated, it remains queryable for your standard retention period; you don’t need to rehydrate the same data multiple times.