If you need to troubleshoot querying in Honeycomb, explore these solutions to common issues.
Troubleshoot issues related to Query Builder.
When you are building a query that contains relational fields, Honeycomb does not allow joined fields in the VISUALIZE clause.
You can get the same effect by swapping the relational field prefix and the primary span (the one without a relational field prefix) in your query and including the primary span in the VISUALIZE clause instead.
For example, if you want to aggregate data to find how many database queries exist on average for transaction X, you might want to write a query that looks at all of transaction X and calculates the SUM of the duration of the database query spans: VISUALIZE SUM (child.duration_ms) WHERE is_root GROUP BY name.
Instead, try: VISUALIZE SUM(duration_ms) WHERE name=db.query GROUP BY root.name.
We do not support relational fields in the Honeycomb Query API by default. Please contact your Honeycomb account team for details.
Use the Query Builder to run queries that contain relational fields.
When you select a new dataset, if the fields in the existing query do not exist in the new dataset, Honeycomb notifies you about the field(s) that were removed from your query.
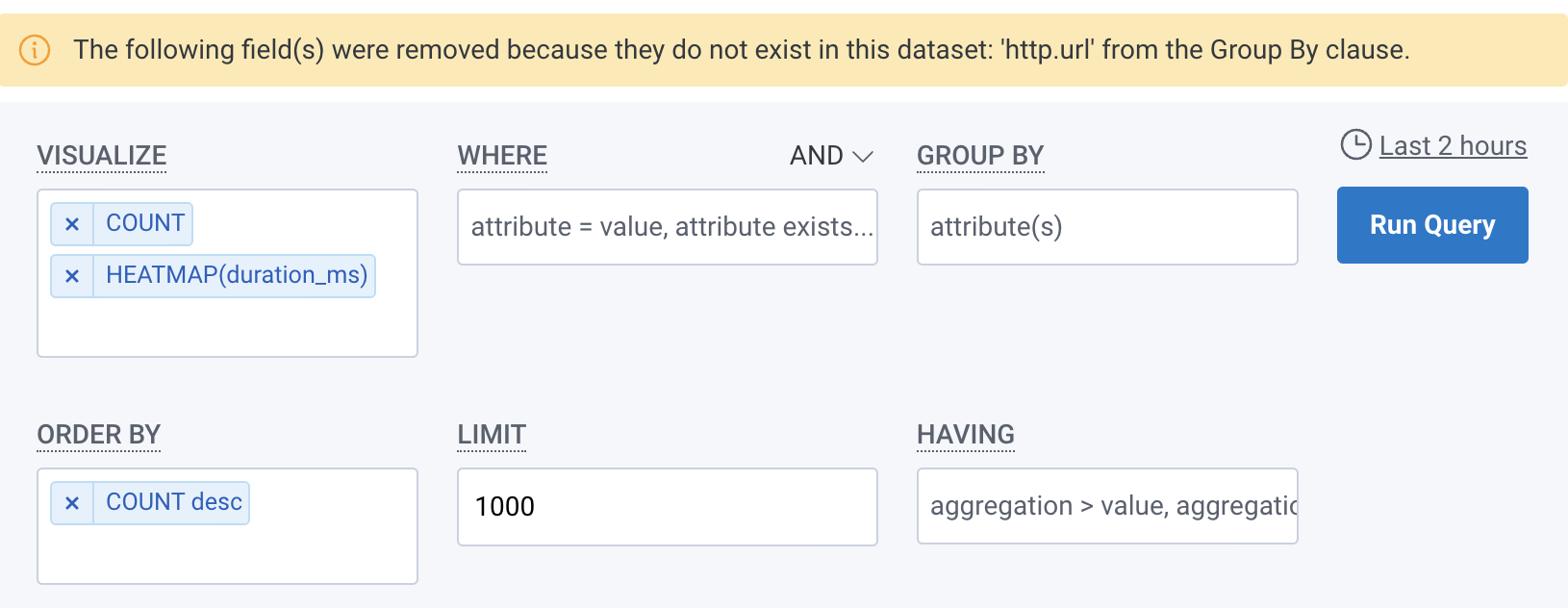
If the fields should be available, make sure the fields in the old dataset exist in the new dataset.
If you are running a query that contains relational fields, your query may take a long time to run. Add more filters to your WHERE clause or reduce your time window.
If you are running a query that contains relational fields, some traces may be missing from your query results. Often, this is because you have many datasets within your environment and relational fields have a built-in joinable time range. When traces exceed the joinable time range for a relational field, they are excluded from the query results.
If you are running a query that contains relational fields, Honeycomb only returns spans that have a matching span to join with.
For example, if you want to find traces that are missing their root span, you might query with a filter of root.name does-not-exist.
This query will only return traces that do have a root span, but the root span is missing a name field.
If the root span is missing entirely, nothing will appear in the results.
Sometimes queries may not return results that are quite what you expect.
If you are running a query that contains relational fields:
Make sure all column names defined in your dataset are distinct from the relational field prefixes.
For example, you should avoid having a column defined in your dataset called root.name because this will collide with the root. relational field prefix, and Honeycomb will try to query the name column on the root span.
Make sure your instrumentation is not accidentally sending duplicate spans.
When Honeycomb finds multiple matching spans for a given prefix, it will choose one to join and ignore the rest.
If a trace has two root spans, only one will be joined for the root. prefix.
If your supplied filters match multiple spans in the same trace and any fields are used in the GROUP BY clause, you may receive confusing results.
Sometimes unexpected query results can also result from Honeycomb’s approach to querying:
If you are running a query that contains multiple anyX. (any., any2., any3.) relational fields, Honeycomb applies them all to the same span.
anyX. and child. relational fields find the first match randomly; they are not ordered as they search through a trace.
When grouping by relational fields, your GROUP BY clause can sometimes function as a filter.
For example, if your query on name returns 100 results that are all root spans, then grouping by parent.name could return 0 results.
Because Query Builder’s main purpose is to produce accurate aggregate numbers, we implement a strict single-match join rather than using the approach taken by traditional relational databases. Each aggregate will only count each primary span (the one without a relational field prefix) in your query once and will only join it with a single other span for each of the available prefixes.
To illustrate how this works, imagine you have a trace with ten leaf spans and another with just one.
You want to get the sum of root span durations for traces that contain leaf spans, so you query with SUM(root.duration_ms) WHERE name=leaf.
An SQL-style implementation would count the first trace’s root duration ten times.
Suppressing duplicates to avoid this would immediately run into trouble if you wanted to add a GROUP BY clause.
Instead, in Honeycomb, you would query with SUM(duration_ms) WHERE trace.parent_id does-not-exist AND any.name=leaf.
When you run a search in the Explore Data view, Honeycomb highlights relevant field names and values in the table display and fields list. To clear highlighted areas, cancel out of your search by selecting x in the search bar.
To learn more about the Explore Data search feature, visit our UI Reference.
Troubleshoot issues related to Query Assistant.
We do our best to produce queries for a broad collection of input, but we cannot guarantee a query for all inputs.
We recommend that you rephrase your input, or try using a different input.
Query Assistant relies on OpenAI’s API, which usually responds in under 5 seconds. If you receive no response to your request after 10 seconds, compute resources for OpenAI’s API are likely unavailable for your request.
We recommend waiting for a few seconds and then trying your request again.
Because Large Language Models (LLMs) are nondeterministic, we cannot guarantee that you will always receive the same query fo the same input, even though we try to be consistent.
To ensure you have a consistent query to run, we recommend saving your query to a Board for later use.
Troubleshoot issues related to Calculated Fields.
We do not support relational fields in Calculated Fields, SLOs, or Triggers. To emulate the functionality of relational fields, propagate the data you would like to see on to the spans so you can filter on them. For example, if you have data on a root span that you would like to be available to a child span, propagate that data to the child spans.
Null or unexpected values in Calculated Fields are usually related to:
Mismatched field types. Many functions are sensitive to the input’s value type.
Review the field types in the schema to ensure they align with the inputs of the functions. If necessary, coerce the fields with a cast operator function.
Name collisions. If data from an event sent to Honeycomb uses the same name as a Calculated Field, the Calculated Field takes priority over the data sent to Honeycomb.
We recommend that you rename the field in your instrumentation or rename the Calculated Field.
When a name collision occurs for a Calculated Field, it may cause confusing behavior in Honeycomb. For example, links that use a duplicate field name may point to the wrong location.
Honeycomb requires that Calculated Fields names be unique across their containing Environment. Calculated Field names should not match the name of any other Calculated Field or any other field in any Dataset contained within the Environment.
When you create a Calculated Field in Honeycomb, we try to check that you have entered a display name that is unique to your Environment (although duplicate names can still occur). If the Calculated Field exists before Honeycomb receives a field name with the same name, we allow both the pre-existing Calculated Field and the new field with the duplicate name to exist, and we display a warning message in the Dataset Settings section of the UI under the Define Schema view.
To resolve this issue, check that your Calculated Field names are unique and not already in use by a field in any Dataset in your Environment. If you find a duplicate name, we recommend renaming the Calculated Field as soon as possible, making sure that the new name is unique to your Environment. If you unable to change the name of the Calculated Field, then change your instrumentation to rename the field instead.
If you rename the field in your instrumentation, you must also delete it in Honeycomb. To do this, use the Column Deletion API. This method will prevent the column from being queried and remove the data in question from new query results, but it will not remove permalinks to existing queries that may contain this data. If you are a Pro/Enterprise user, support can help you with deletion. To request help, visit Honeycomb Support to create a ticket for our support team, or email support@honeycomb.io.
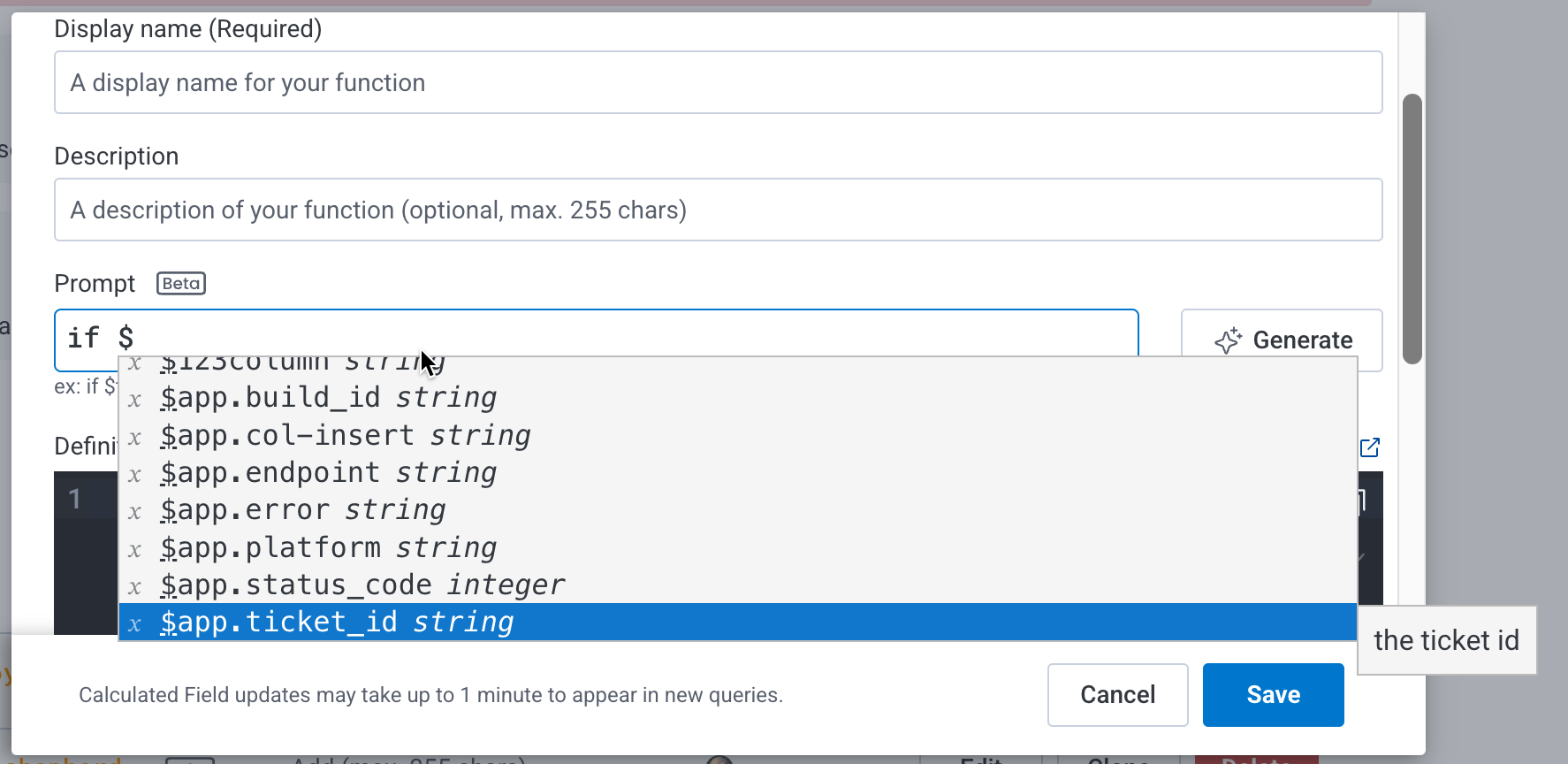
This error message means your entered Calculated Field prompt did not reference at least one field using the required $ syntax.
To resolve this issue, start each field with the $ symbol, such as $field_name.
When using natural language to create a Calculated Field in Honeycomb, you must explicitly reference schema fields in your Dataset or Environment using the $ syntax.
For example, within the prompt:
Extract the directory after "/api" in $url_path — url_path is the field nameif $span.kind = "server" and $trace.parent_id does not exist, return whether $duration_ms < 500 or $http_status_code < 400 — span.kind, trace.parent_id and duration_ms are the field namesif $error exists and contains "trace", return $error — error is the field nameAs you type the $ symbol in the prompt display, Honeycomb shows a dropdown of available fields to select.
Use this feature to select exactly which fields to use in your prompt expression.
This error message means the AI could not find one or more entered fields with the $ syntax in your Calculated Field prompt.
To resolve this issue:
double-check that each column name you reference (for example, $field_name) exactly matches a field in your schema.
avoid typos by typing $ in the prompt display and selecting the target field from the dropdown that appears. This ensures the use of a valid field name.