If not yet ready to use OpenTelemetry, you can use the Honeycomb Lambda Extension.
This extension is designed to run alongside your Lambda Function.
It integrates with the Lambda Logs API and receives log messages from your lambda function, which are then sent to Honeycomb as events.
Structured log messages sent to stdout or stderr from your lambda function will be sent to Honeycomb as events.
The extension can be run inside a container or added as a Lambda Layer.
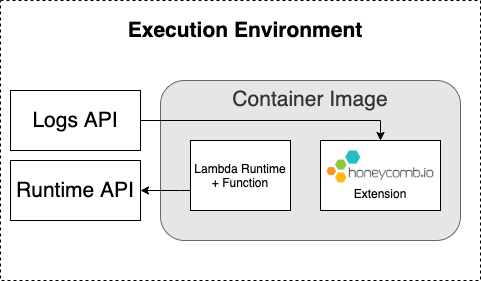
AWS Lambda Extensions allow you to extend the functionality of Lambda functions through configuration as Lambda Layers or run inside a container image.
Extensions run alongside the Lambda Runtime and can read data environment variables from the environment.
Once the Honeycomb Lambda Extension is configured, any structured logs emitted to stdout or stderr by your Lambda function will be parsed by the extension and sent to a dataset that you specify in Honeycomb.
The Honeycomb Lambda Extension is available as an external extension pre-built in a lambda layer for either x86_64 or arm64 architectures.
arm64 is supported in most, but not all regions.
See AWS Lambda Pricing for which regions are supported.To start using the Honeycomb Lambda Extension, add the extension to your function as a Lambda Layer.
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:af-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:af-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ca-central-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ca-central-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-central-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-central-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-north-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-north-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-3:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:me-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:me-south-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:sa-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:sa-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-east-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-east-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-east-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-west-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-west-1:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-west-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-west-2:702835727665:layer:honeycomb-lambda-extension-arm64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:af-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:af-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-northeast-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-northeast-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ap-southeast-4:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ap-southeast-4:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:ca-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:ca-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-central-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-central-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-north-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-north-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-south-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-south-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:eu-west-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:eu-west-3:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:me-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:me-central-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:me-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:me-south-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:sa-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:sa-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-east-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-east-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-east-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-west-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-west-1:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
aws lambda update-function-configuration --function-name YourFunctionName \
--layers "arn:aws:lambda:us-west-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"
You can also use infrastructure-as-code tools such as Terraform:
resource "aws_lambda_function" "extensions-demo-example-lambda" {
function_name = "HoneycombExtensionExample"
...
layers = ["arn:aws:lambda:us-west-2:702835727665:layer:honeycomb-lambda-extension-x86_64-v11-1-2:1"]
}
Add the following environment variables to your Lambda function configuration:
LIBHONEY_DATASET - The Honeycomb dataset you would like events to be sent to. This could be the service name representing the function or a generic dataset name representing the data.LIBHONEY_API_KEY - Your Honeycomb API Key (also called Write Key).As well as the following optional environment variable:
LIBHONEY_API_HOST - Mostly used for testing purposes, or to be compatible with proxies.
Defaults to https://api.honeycomb.io/.LOGS_API_DISABLE_PLATFORM_MSGS - Optional.
Set to “true” in order to disable “platform” messages from the logs API.HONEYCOMB_DEBUG - Optional.
Set to “true” to enable debug statements and troubleshoot issues.
Enabling this will subscribe to Libhoney’s response queue and log the success or failure of sending events to Honeycomb.HONEYCOMB_BATCH_SEND_TIMEOUT - Optional.
Default: “15s” (15 seconds; refer to note below about timeout durations).
The timeout for the complete HTTP request/response cycle for sending a batch of events Honeycomb.
A batch send that times out has a single built-in retry; total time a lambda invocation may spend waiting is double this value.
A very low duration may result in duplicate events, if Honeycomb data ingest is successful but slower than this timeout (rare, but possible).HONEYCOMB_CONNECT_TIMEOUT - Optional.
Default: 3s (3 seconds; refer to note below about timeout durations).
The timeout for establishing a TCP connection to Honeycomb.
This is useful when there are connectivity issues between your Lambda environment and Honeycomb, allowing upload requests to fail faster and avoid waiting for the longer batch send timeout to elapse.AWS Lambda functions can now be packaged and deployed as container images. This allows developers to leverage the flexibility and familiarity of container tooling, workflows and dependencies.
To run the Honeycomb Lambda Extension inside your container image, you must download the extension and place it in the /opt/extensions directory of your image.
FROM amazon/aws-lambda-ruby:2.7
ARG FUNCTION_DIR="/var/task"
RUN mkdir -p /opt/extensions
RUN yum install -y curl
RUN curl -L https://honeycomb.io/download/honeycomb-lambda-extension/v11.1.0/honeycomb-lambda-extension-<ARCH> -o /opt/extensions/honeycomb-lambda-extension
RUN chmod +x /opt/extensions/honeycomb-lambda-extension
RUN mkdir -p ${FUNCTION_DIR}
COPY . ${FUNCTION_DIR}
ENV LIBHONEY_API_KEY <HONEYCOMB_API_KEY>
ENV LIBHONEY_DATASET <HONEYCOMB_DATASET>
CMD ["app.handler"]
Replace <ARCH> with the appropriate architecture (x86_64 or arm64) based on your container image.
AWS Lambda provides a number of base images you can use. You can also use a custom base image, and adjust the examples accordingly.
The Honeycomb Lambda Extension runs independently of your Lambda Function and does not add to your Lambda Function’s execution time or add any additional latency. However, it does increase your Lambda Function’s size in proportion with the size of the Honeycomb Lambda Extension binary.
Below are some structured logging examples using some libraries we are familiar with at Honeycomb. Feel free to use your own!
import (
log "github.com/sirupsen/logrus"
)
log.SetFormatter(&log.JSONFormatter{})
func Handler(ctx context.Context) error {
// Measure execution time
startTime := time.Now()
// ...
// Get the Lambda context object
lc, _ := lambdacontext.FromContext(ctx)
log.WithFields(log.Fields{
"function_name": lambdacontext.FunctionName,
"function_version": lambdacontext.FunctionVersion,
"request_id": lc.AwsRequestID,
"duration_ms": time.Since(startTime).Milliseconds(),
// other fields of interest
}).Info("Hello World from Lambda!")
}
import structlog
structlog.configure(processors=[structlog.processors.JSONRenderer()])
log = structlog.get_logger()
def handler(event, context):
# measure execution time
start_time = datetime.datetime.now()
# ...
log.msg(
"Hello World from Lambda!",
function_name=context.function_name,
function_version=context.function_version,
request_id=context.aws_request_id,
duration_ms=(datetime.datetime.now() - start_time).total_seconds() * 1000,
# other fields of interest
)
var bunyan = require('bunyan');
var log = bunyan.createLogger();
module.exports.handler = (event, context, callback) => {
// Measure execution time
let startTime = Date.now();
// ...
log.info({
functionName: context.functionName,
functionVersion: context.functionVersion,
requestId: context.awsRequestId,
// Example fields - send anything that seems relevant!
userId: event.UserId,
userAction: event.UserAction,
latencyMs: Date.now() - startTime,
},
'Hello World from Lambda!');
}
console.log to write structured log lines in Lambda.
Lambda uses a patched version of console.log, injecting extra information with each line that does not work correctly with the Honeycomb Extension Lambda Logs integration.