

Overview
In the next 10 minutes, you will create a series of OpenTelemetry Collectors that will work together to pull in the correct telemetry and apply Kubernetes-specific data to it, which will help correlate issues. Your implementation will also lay the foundation for your applications to send telemetry data, if you choose to instrument them.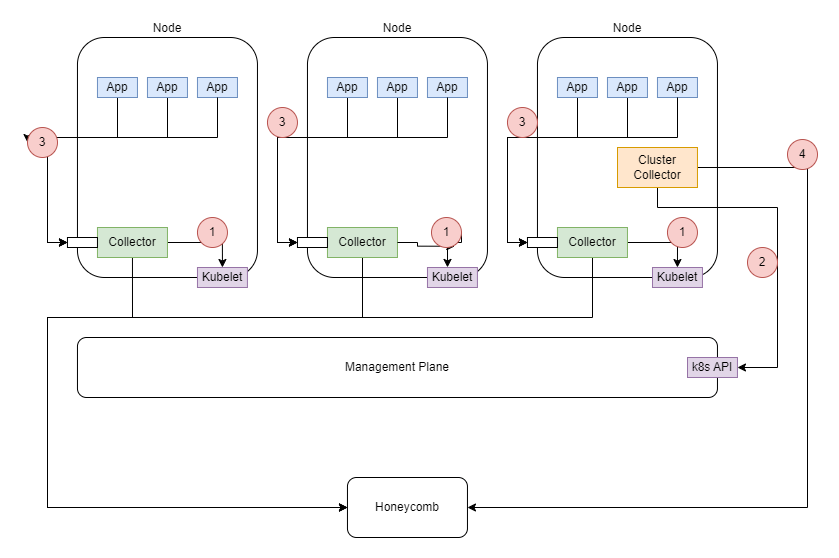
- Each node will contain a Collector, which will use the node’s Kubelet API to gather metrics data about the node and the node’s pod resources.
- The entire cluster will contain a separate Collector, which will use the Kubernetes API to get details about Kubernetes Events, such as active deployments.
- Applications will be able to use the node’s IP address to send telemetry data (logs, metrics, and traces) to the Collector that is local to the node, if you instrument them.
- Each Collector will send telemetry data directly to Honeycomb over gRPC.
Collected Data
When you finish, you will have access to:- Default metrics provided by Kubelet Stats for nodes and pods, plus the optional
uptime,*_request_utilization, and*_limit_utilizationmetrics - Default Kubernetes Cluster metrics
- All Kubernetes events from the cluster
- Additional Kubernetes metadata, plus all the pod’s labels and annotations as resource attributes whenever possible, including:
k8s.namespace.namek8s.deployment.namek8s.statefulset.namek8s.daemonset.namek8s.cronjob.namek8s.job.namek8s.node.namek8s.pod.namek8s.pod.uidk8s.pod.start_time
Before You Begin
Before beginning this guide, you should have:- Created a running Kubernetes cluster.
- Installed the
kubectlcommand-line utility locally. - Installed Helm 3.9+ locally.
- Deployed some applications to Kubernetes.
Step 1: Create a Namespace
To help you manage your objects in the cluster, create a namespace to contain the collector infrastructure. In this example, we call the namespacehoneycomb.
Step 2: Configure Kubernetes with Your Honeycomb API Key
Within your new namespace, create a Kubernetes Secret that contains your Honeycomb API Key. You can find your Honeycomb API Key in your environment in Honeycomb.Step 3: Add OpenTelemetry’s Helm Repository
OpenTelemetry’s Helm GitHub repository includes Helm charts with all of the resources you need to deploy Collectors to your Kubernetes cluster.-
Add the repo:
-
Update your repos to ensure Helm is aware of the latest versions:
Step 4: Deploy Collectors
Deploy your Collectors:- A Deployment-mode Collector to collect your cluster metrics.
- A DaemonSet-mode Collector to collect application telemetry data and metrics from your cluster’s node(s).
- US Instance
- EU Instance
If Collector installation fails and returns an error like the following:Make sure you have Helm 3.9+ installed, as older Helm versions typically cause this error.
Step 5: Verify the Collector Installation
Check that the Collectors are installed by using thekubectl command to see if the pods are running:
The result should contain one pod running under a name containing the prefix
otel-collector-cluster, and one pod running under a name containing the word agent for each node in your Kubernetes cluster.- Receive tracing data from service applications in your cluster and forward it to Honeycomb.
- Gather and send metrics data from all of the pods in your cluster.
- Gather and send metrics data about the nodes in your cluster.
Explore Your Data in Honeycomb
After a few minutes, data should start flowing into Honeycomb. To explore metrics related to your Kubernetes cluster, log in to Honeycomb and query thek8s-metrics dataset in your environment.
Try asking the Query Assistant questions like:
- “Show me the average CPU of my pods”
- “What’s the P99 memory usage of my nodes?”
k8s-events dataset. These may be a little harder to understand, so try asking the Query Assistant questions like:
- “Show me the pods that have a reason of Started”
- “Show me pods that are crashing”
What’s Next?
Now that you have created an observability pipeline and have gotten some metrics, you can use these to get even more visibility into your Kubernetes cluster.- Configure your applications to send data to the OpenTelemetry Collectors Have you already instrumented your applications with OpenTelemetry? You’ll need to configure your pods and applications to send data to your new Collectors.
- Add low-code, automatic instrumentation to your applications Do you want more insight into your application data, but can’t fully instrument your code yet? You can get even more insight by using the OpenTelemetry Operator to automatically instrument your applications. To learn more, visit Low-Code Auto-Instrumentation with the OpenTelemetry Operator for Kubernetes.