

- understand how data flows through your systems
- identify errors
- find performance issues
Access a Trace
The trace detail view is accessible through:- points in a visualization
- the trace button ()
- directly with a permalink
- From Query Builder
- From Traces Tab
- From Explore Data Tab
- In Query Builder, SELECT with any clause. This creates the visualization below the Query Builder.
-
Select a point in the visualization.
Choose from a line graph or from a Heatmap.
From a line graph:
From a Heatmap:
-
In the menu that appears, select View trace.
The next screen displays a trace detail view.
The displayed trace is the slowest trace with a child span and with a value is less than or equal to the value of your selected point.
Therefore, selecting a point on the
p90graph gives a different trace than selecting a point on an overlaidp10graph. You will be automatically taken to the first span in the trace waterfall that matches the query’s filter criteria. Selecting on a point in a graph with an empty WHERE clause will direct you to the root span in the trace waterfall.
Interact with Traces
The trace detail view displays information in four areas:- trace identification with navigation and trace ID
- trace summary with trace metadata
- waterfall representation of spans with search and customization options
- trace sidebar with details about the selected span
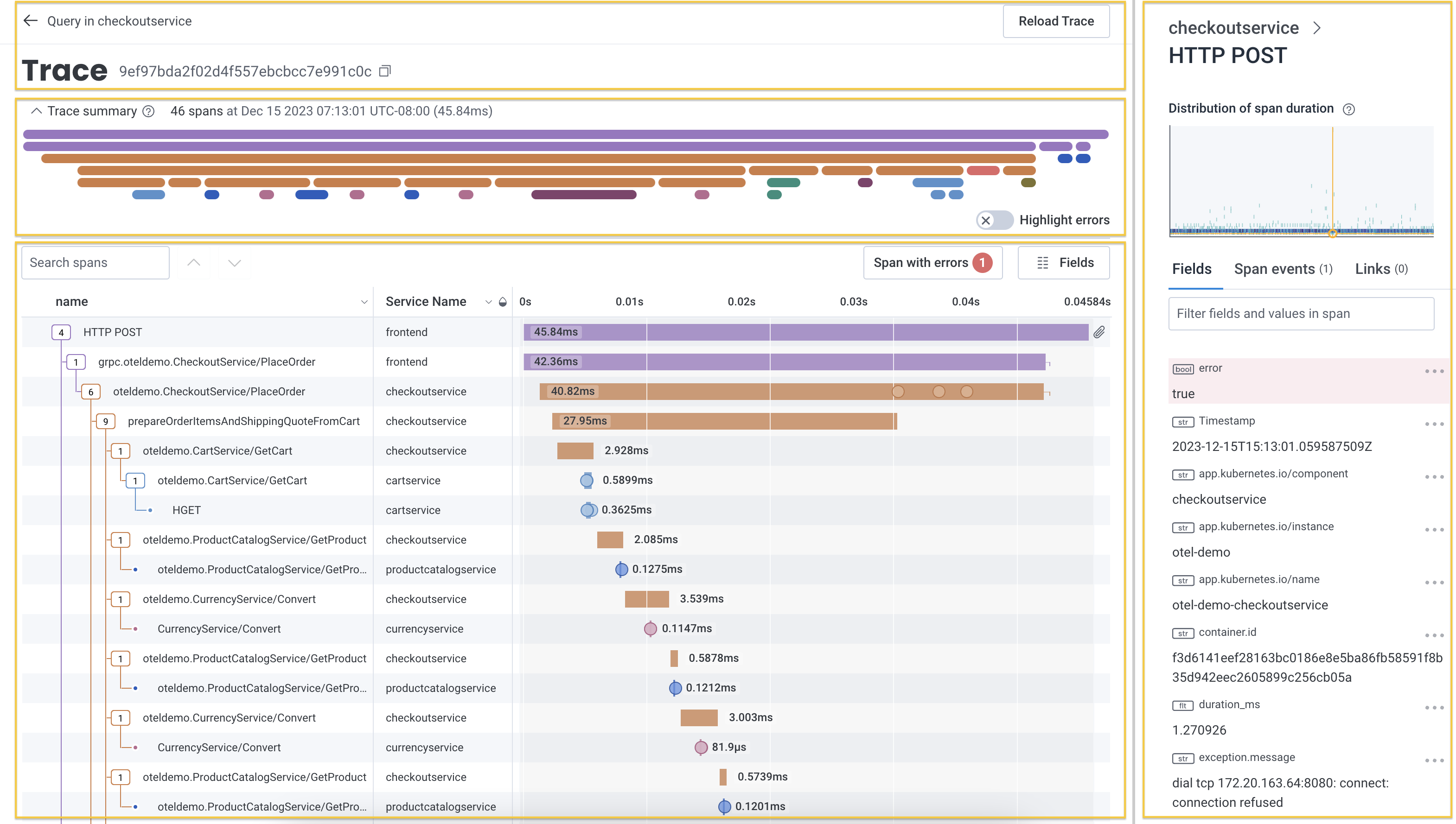
Trace Identification
Each trace has a unique identifier presented at the top of page along side navigation elements.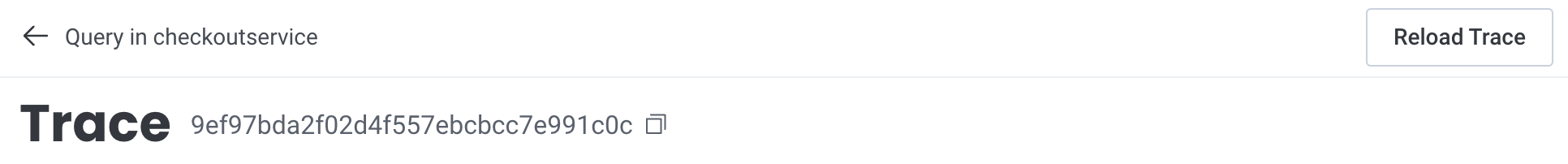

Trace Summary
The trace summary displays important metadata and provides a condensed view of the trace waterfall diagram. Metadata about the trace includes its total number of spans, the timestamp of the root span, and the total trace duration. Use this view to find long-running spans and spans with errors within your trace without scrolling through the entire trace waterfall. Expand or collapse the summary view by selecting the directional caret.
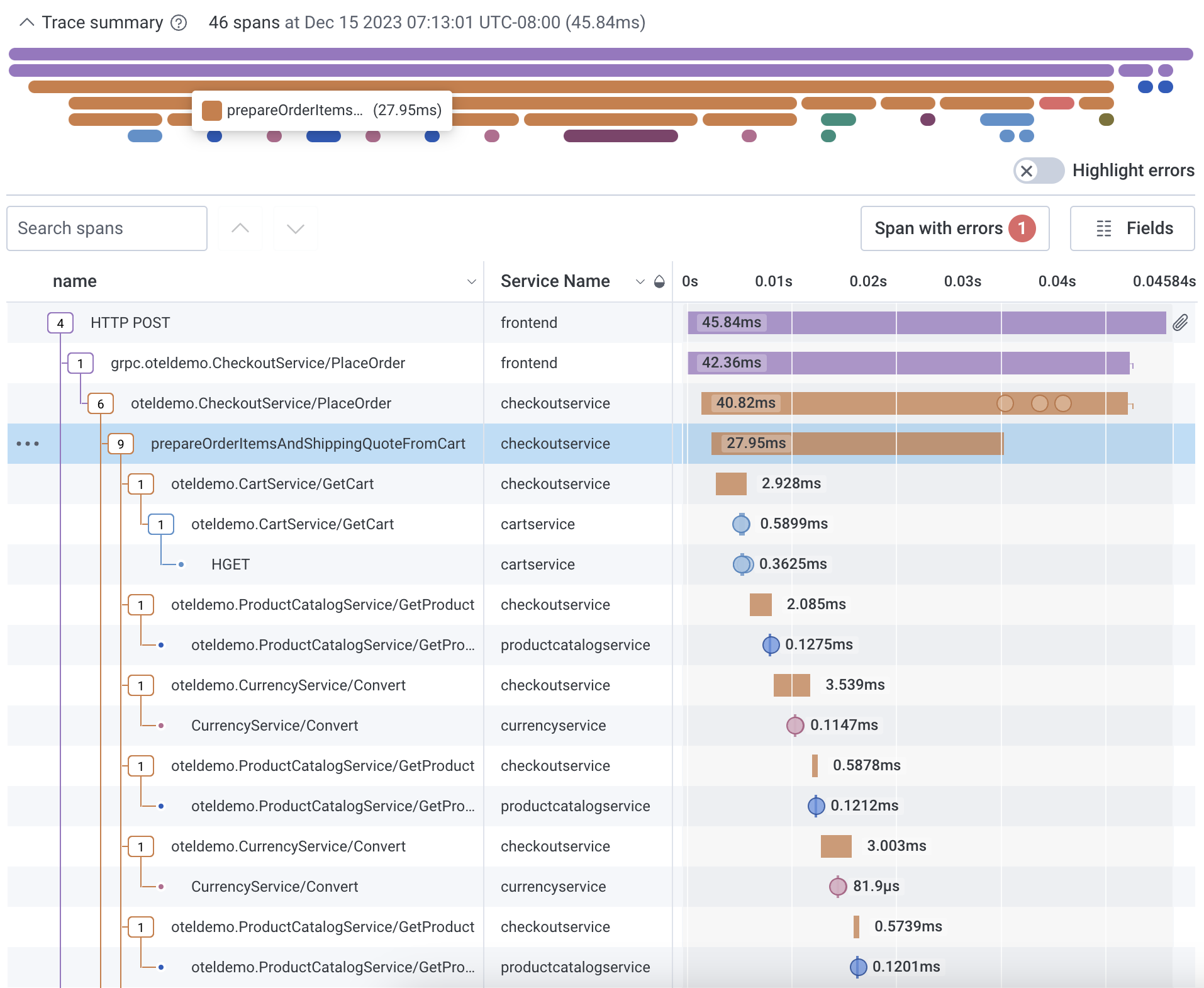

Waterfall Representation
Honeycomb uses the metadata from each span to reconstruct the relationships between them and generate a trace diagram. This is also called a waterfall diagram because it shows how the order of operations cascades across the total execution time.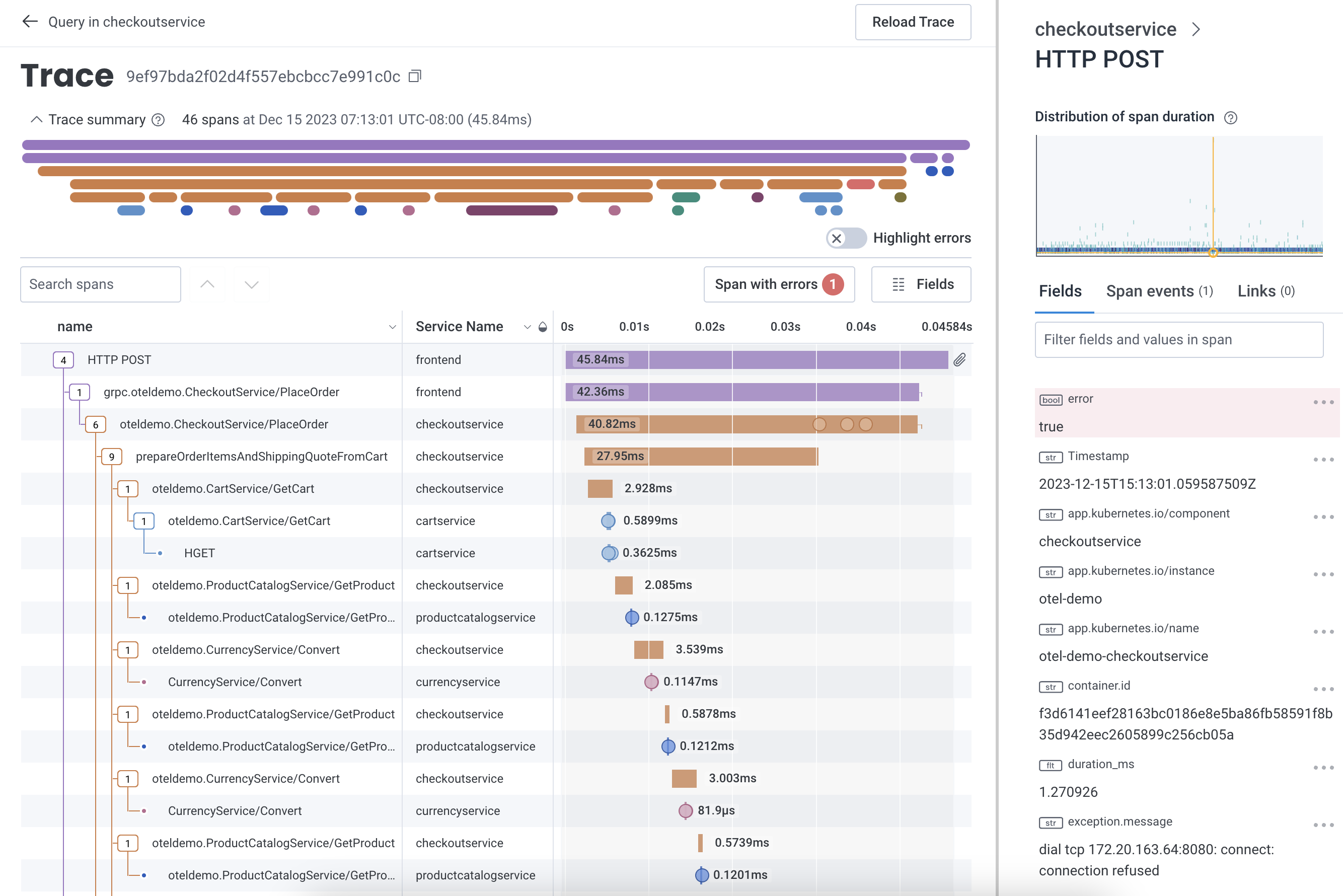
Collapse and Expand Spans
When a trace contains many spans, it can be useful to collapse spans that are not of interest, or expand specific parent spans to investigate. Navigate the diagram with either mouse or keyboard navigation.- Mouse
- Keyboard
Select a span through mouse clicks.For a specific parent span, collapse or expand all the dependent spans by selecting the parent span’s dependent count box.
When collapsed, the count box changes from an outlined box to a filled box, and the number changes from the number of direct children to the total size of the subtree.To collapse or expand spans in batch, select the three dots to the left of a targeted span to open its context menu.
Menu options include:
- Collapse spans at this depth
- Collapse spans with this ServiceName and Name
- Expand spans at this depth
- Expand spans with this ServiceName and Name
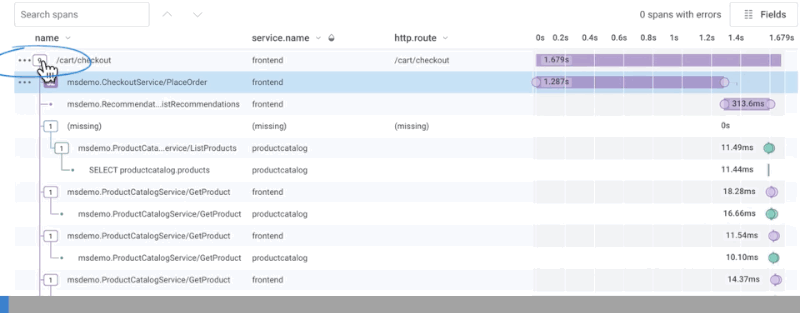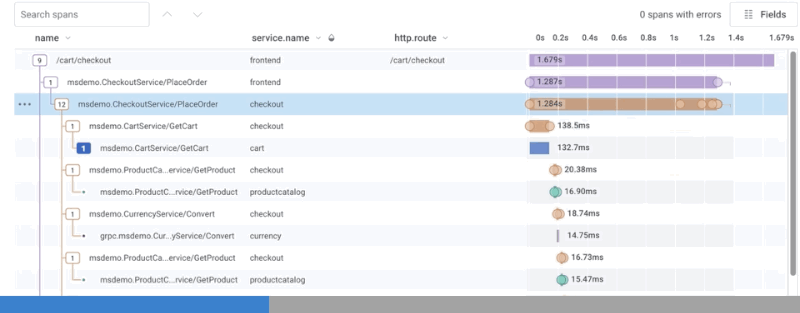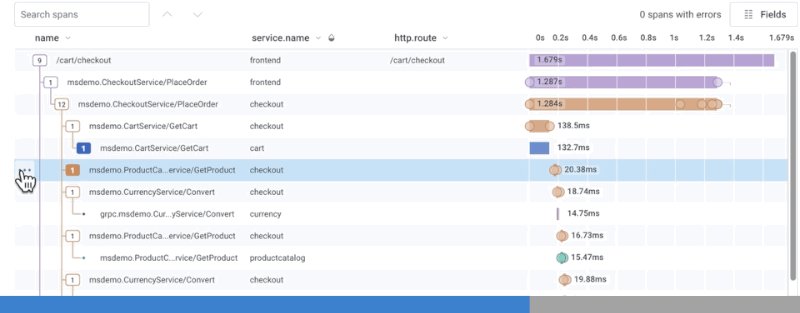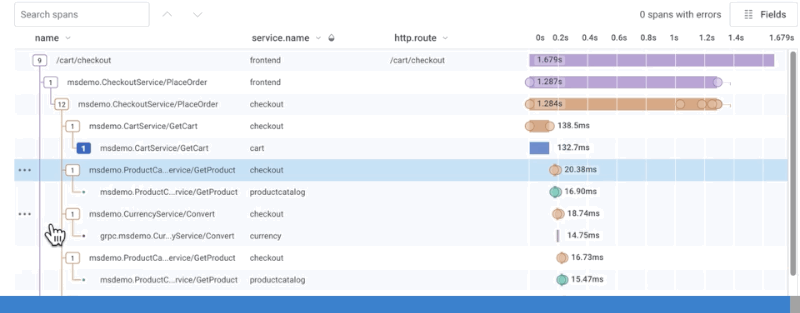
Zoom In and Share Subtrees in the Waterfall
To zoom into a subtree within the trace waterfall view, select the Zoom In icon () next to any parent span. The timeline re-adjusts to that parent span’s duration, and shows the duration of all children spans relative to that parent span, as opposed to the whole trace. The trace summary view also highlights which span is being examined in zoom mode. Zoom out of the subtree by selecting the Zoom Out icon (). Permalinks for subtrees in zoom mode exist. Copy the URL link in your web browser and share the URL with other users to view the same subtree.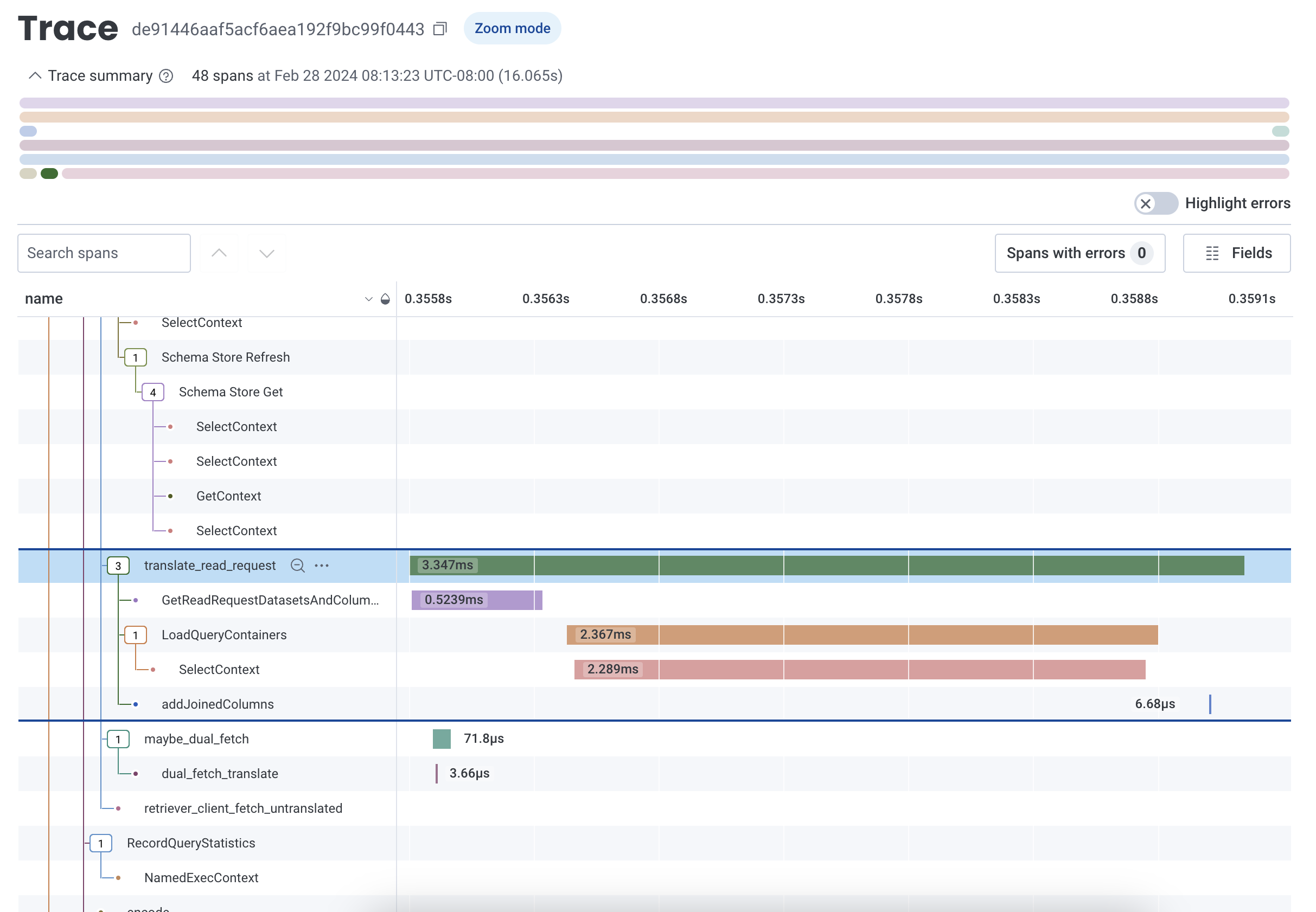
Customize Waterfall Representation
The search field provides the ability to type in a field or value and highlights spans that contain your search term. Error Highlighting shows how many spans with errors exists in the trace. The Fields button customizes the fields in the waterfall representation.Search Spans
To search spans, use the search box to type in the field or value you want to find. As you type, the display changes and highlights any spans that contain your search term. A count of matching spans found appears next to the search box and navigation arrows. Use the navigation arrows to move between the spans that match the search term.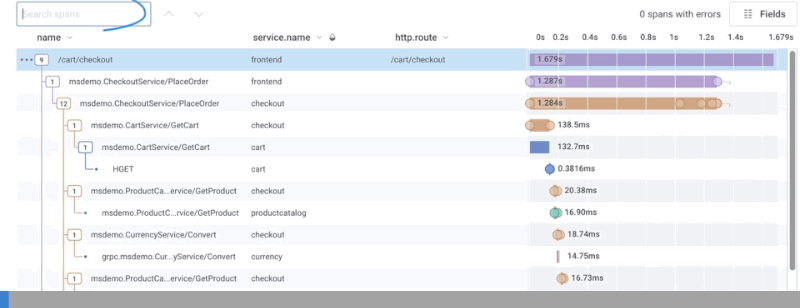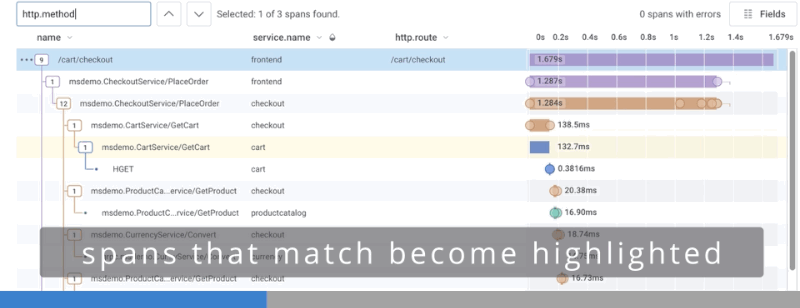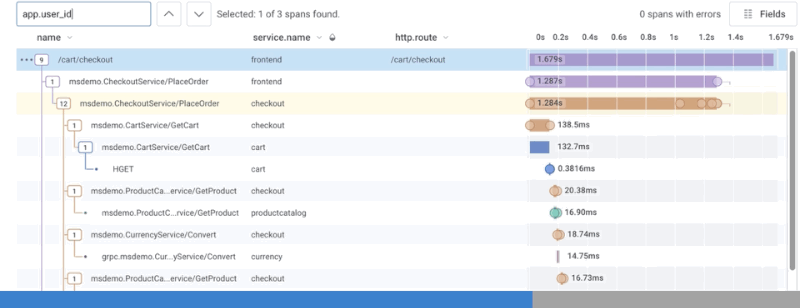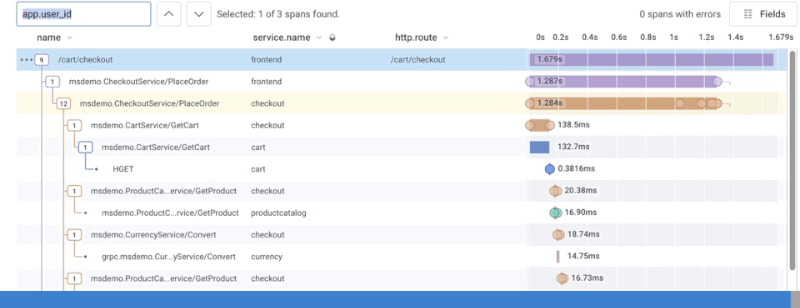
Error Highlighting
The count of spans containing errors is displayed above the trace waterfall. Select this count of spans to navigate between the spans with errors. By default, spans that contain errors are displayed in red. The error field is also highlighted at the top of the field list in the trace sidebar. Span error detection is based on the Error field as configured in the Dataset Definition.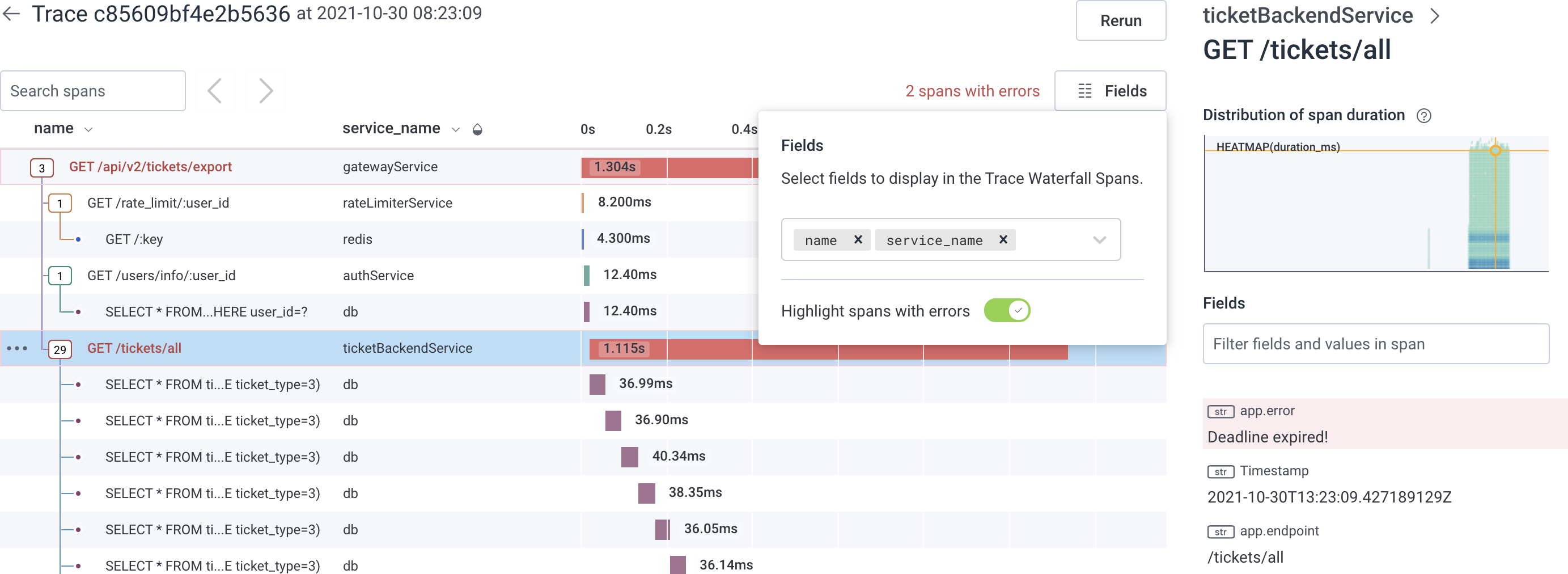
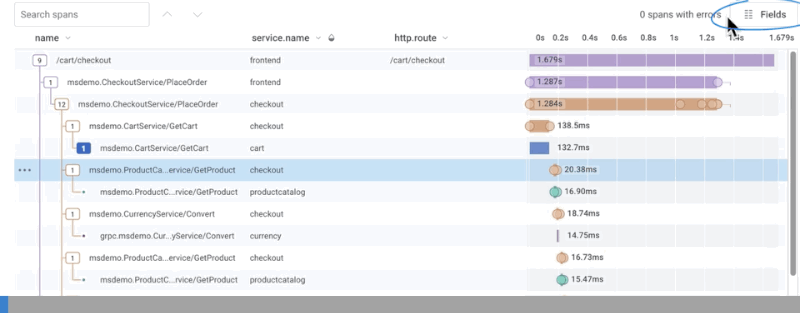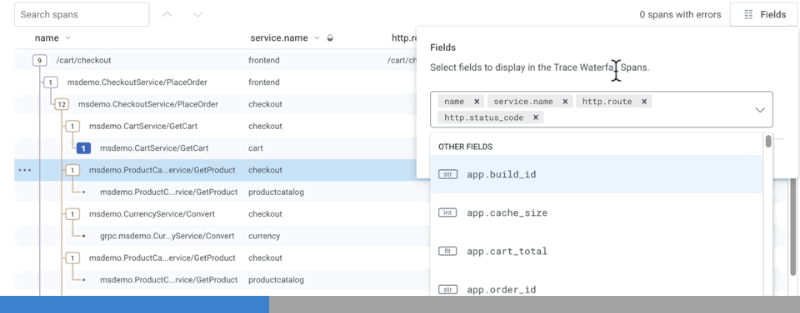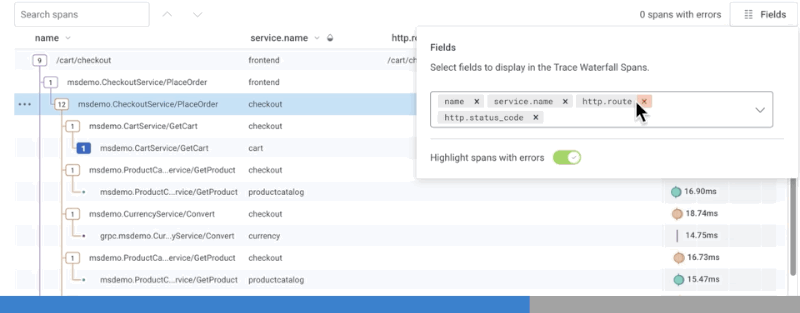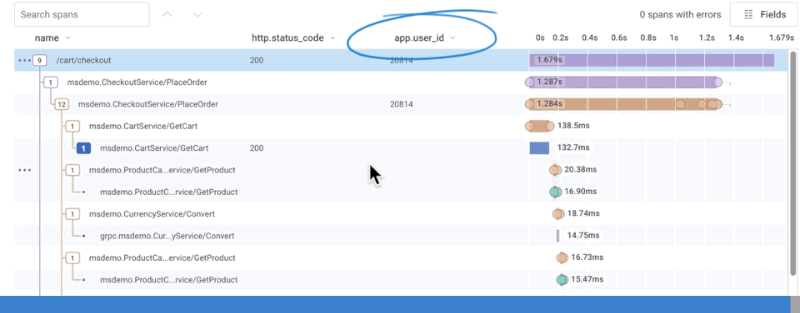
Customize Fields in Waterfall Representation
To add a field to the waterfall representation, use the Fields button in the upper right corner and type in the target field name. A list of suggested fields appears based on your input. To update the waterfall representation, complete typing the field name and pressEnter, or select the target field name from the list of suggested fields.
The waterfall representation updates with a new column labeled with the field name and its information.
To remove fields in the span display, use the Fields button to display the current fields.
Use the x to right of each field name to remove it.
The display updates after any change.
Resize Columns in Waterfall Representation
To resize columns in the waterfall representation, drag the gray borders that separate column names to your desired width. A set minimum width exists for each column. To remove a column completely, use the Fields button.
Change Color in Waterfall Representation
The color for each span applies to its entire row, such as the count box, relationship tracing, and duration representation. By default, the color is determined byservice.name if there is more than one service name defined; otherwise, they are colored by name.
A half-filled water drop () appears next to the column header of the determining field.
Each distinct value in the determining field gets its own color.
Changing the determining field colors the waterfall display differently and may emphasize different attributes.
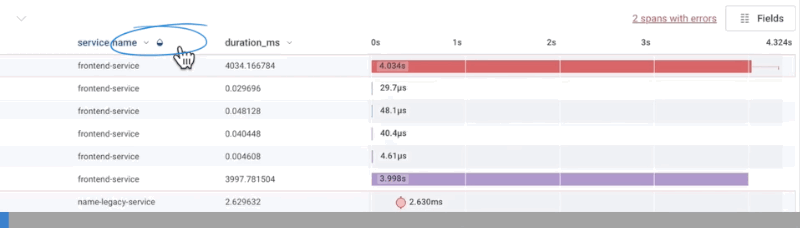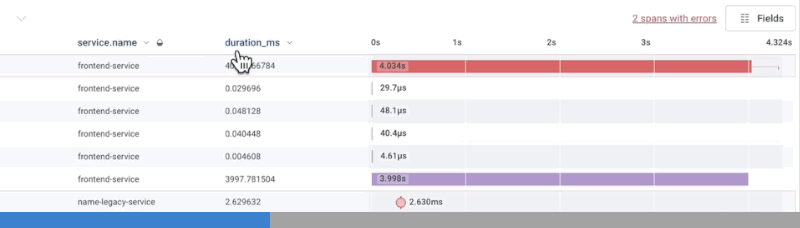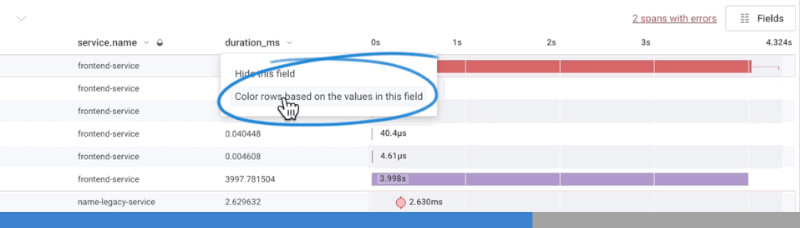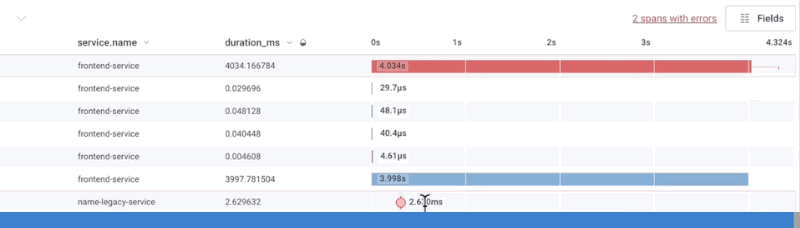
To change the determining field, select the target field’s column header.
In the menu that appears, select Color rows based on the values in this field.
The display refreshes with the new color scheme, and the water drop icon () appears next to the selected field’s column header.
Trace Sidebar
When a span is selected, the trace sidebar updates with details about the span, including its fields, span events, and links. The Span Events tab of the trace sidebar displays details about span events, if applicable. To access, navigate to the Span Events tab and select the Span Event name to show its details. Alternatively, in the waterfall diagram, select the circle that represents a span event to display the span event’s details in the trace sidebar’s Span Events tab. The Links tab of the trace sidebar displays details about span links, if applicable. To access, navigate to the Links tab to view span link details. Alternatively, in the waterfall diagram, select the link icon () that represents a span link to display details in the trace sidebar’s Links tab.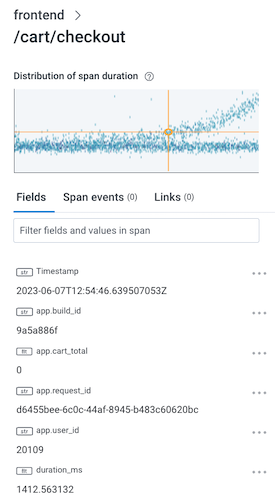
The Minigraph
The minigraph, at the top of the trace sidebar, shows a heatmap view of the selected span relative to others with the same fields displayed in the waterfall. Selecting anywhere in the minigraph sends you to the Query Builder display with a query that corresponds to the minigraph.Trace Sidebar Filter
The trace sidebar includes a filter. Enter terms into this sidebar filter and the sidebar display refreshes to show matching fields and/or values. This filter remains in the trace sidebar as you select different spans. Use this behavior to track a particular field as you move between a set of spans.Refine and Return to The Query Builder
Any span’s field or value can act as an entry point back to the Query Builder. In the Trace Sidebar, select the three dots to the right of a targeted field to open its context menu. In addition to copy options, the menu includes GROUP BY and WHERE actions, which create a new query that re-uses the original query but adds the selected clause and field.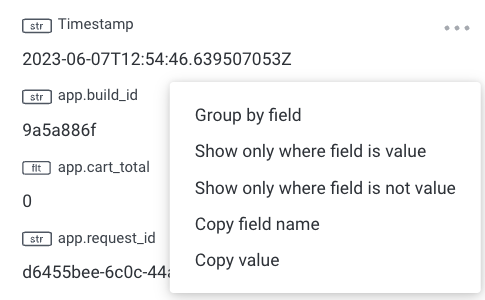
The new query may not return results.
If the fields you select are only found on child spans, but the original query includes
trace.parent_id does-not-exist or is_root, then the new query will be self-contradictory, and will not return any results.
Remove any unneeded clauses to get a full result.Gen AI tab
When investigating traces from a generative AI agent or application, the trace sidebar includes a dedicated Gen AI tab that surfaces AI-specific context alongside the standard Fields, Span Events, and Links tabs. In the Gen AI tab you can see what messages were exchanged, what model was used, how many tokens were consumed, and if response quality evaluations passed without manually scanning raw span fields.When the Gen AI tab appears
The Gen AI tab appears in the trace sidebar when the selected span includes agen_ai.operation.name attribute. This attribute is defined by the OpenTelemetry Generative AI semantic conventions and identifies the span as a GenAI operation.
If a span does not include gen_ai.operation.name, the Gen AI tab will not appear for that span.
What appears in the Gen AI tab
When the Gen AI tab is active, Honeycomb renders the contents of GenAI-specific span fields in a structured, human-readable format. Messages such as user inputs, assistant responses, and tool call results render as formatted markdown when possible, making long or structured outputs easier to read. Gen AI fields also appear in the waterfall representation, so you can see key metadata like model name alongside the span’s duration and hierarchy at a glance.Viewing evaluation results
Evaluation results can be viewed either on the Gen AI tab or on the Span Events tab, depending on your instrumentation. If your instrumentation attachesgen_ai.evaluation.result events to a span, those evaluation results appear in the Span Events tab of the sidebar.
To view evaluation events on the Gen AI tab, they must be attached to a GenAI span that has gen_ai.operation.name set. From the Gen AI tab, select the gen_ai.evaluation.result event name to expand its details. You can also find them in the Span Events tab.
Instrumenting your AI application
To enable the Gen AI tab, your instrumentation must emit spans that follow the OTel GenAI semantic conventions. Honeycomb recommends that each GenAI span includes:gen_ai.operation.name: triggers the Gen AI tab in the trace view (required by Honeycomb)
gen_ai.input.messages: the chat history sent to the modelgen_ai.output.messages: the model’s response
gen_ai.usage.input_tokensgen_ai.usage.output_tokens
gen_ai.evaluation.result span events to a GenAI operation span, following the OTel GenAI events spec.
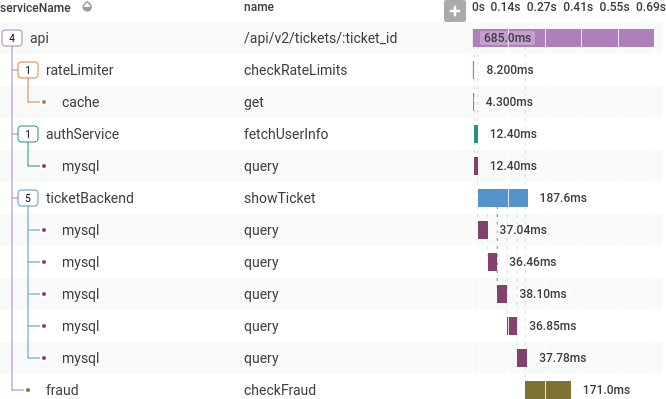
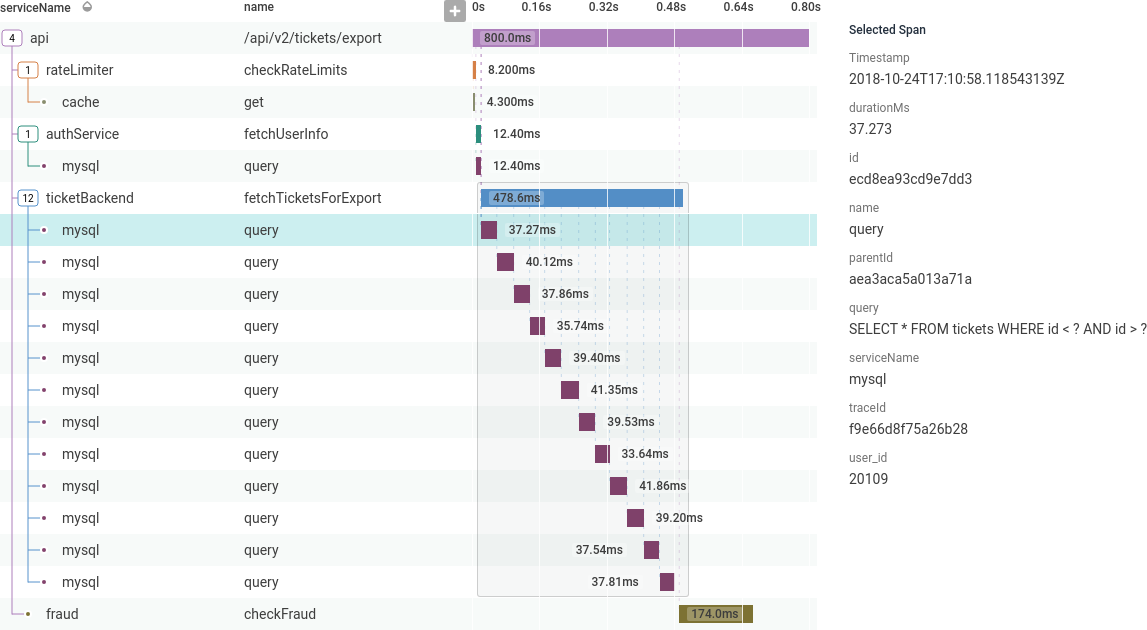
Example: Slow API Calls
Here is an example of investigating a problem using tracing: A few users are reporting slow API calls. The initial investigation shows one endpoint is periodically slow. One user is making a lot of calls, and that is slowing down responses for everyone.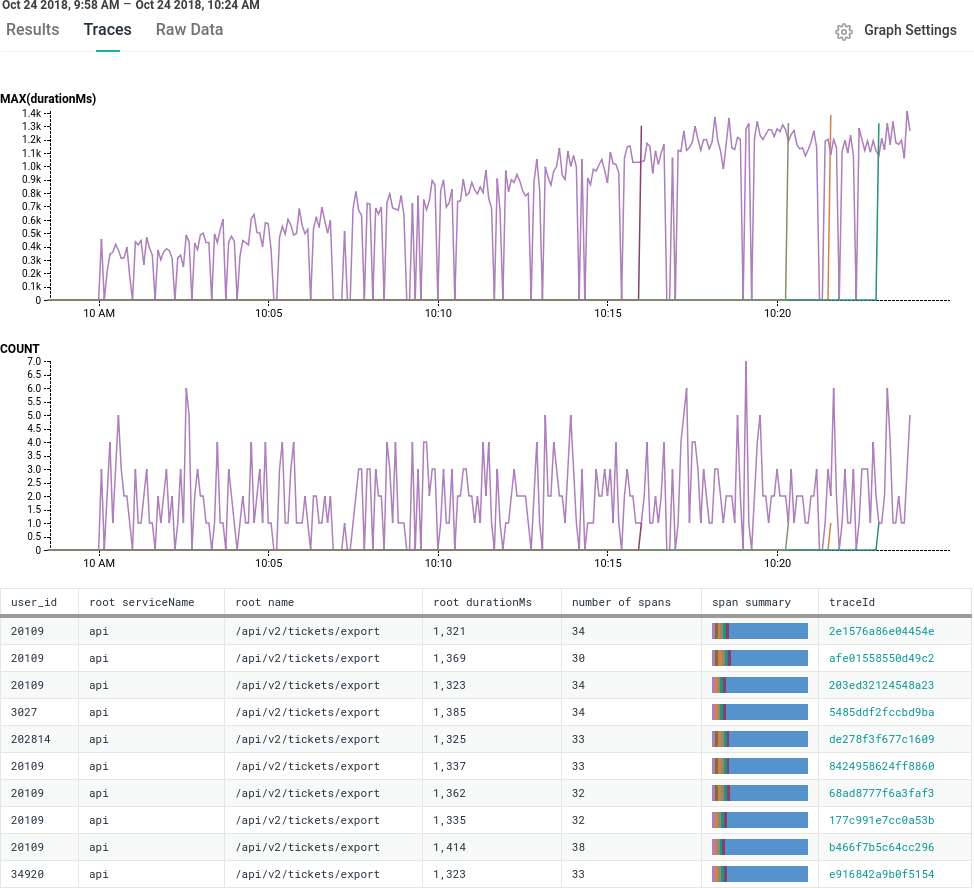
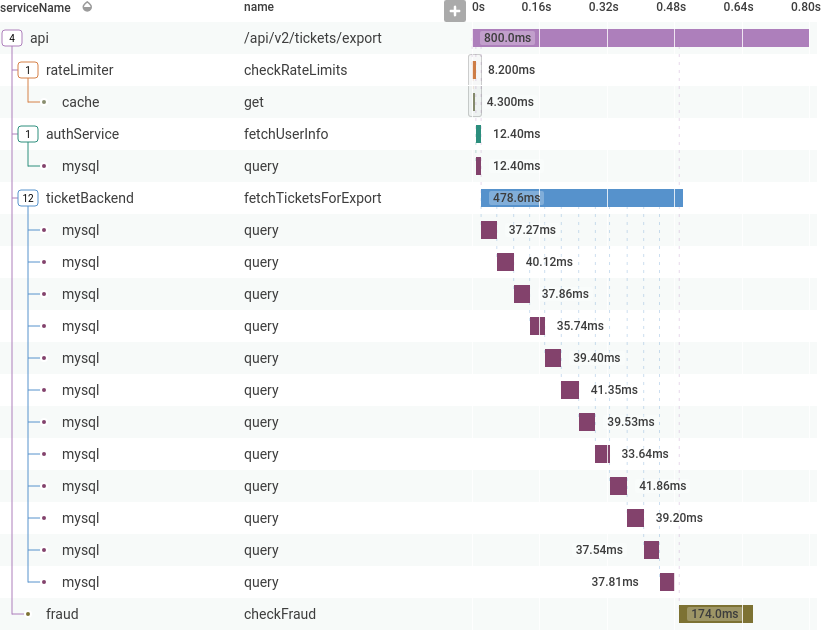
ticketBackend is making more calls than expected to mysql.
Clicking on one of the mysql spans shows more information about it in the sidebar, including the specific database query.
Enhance a Trace with Archived Data
This feature is available as an add-on for the Honeycomb Enterprise plan.
Please contact your Honeycomb account team for details.
-
From the Trace Waterfall view, select Enhance from Archive.
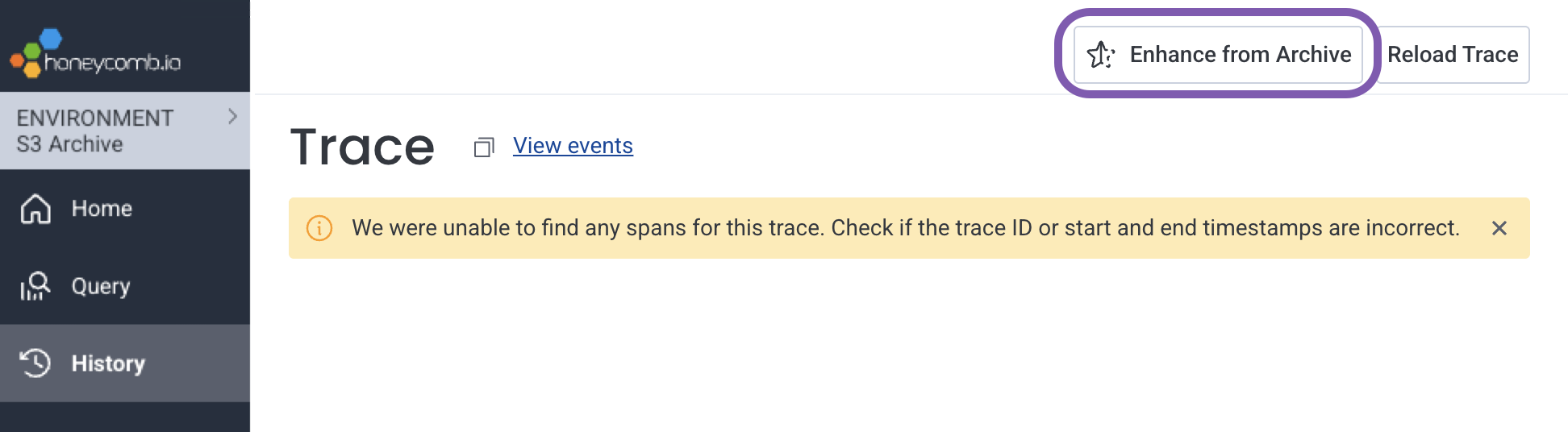
-
In the modal, review the automatically-populated scope of your rehydration:
-
Review your usage estimate to confirm:
- Approximate number of events based on the average size of previously rehydrated events
- Approximate number of free monthly rehydration events that will be used and free events remaining
- Approximate regular monthly events that will be used and regular events remaining
- Select Rehydrate data to ingest the missing spans. You will be redirected to the History () page in your Amazon S3 Environment.