

New to running queries in Honeycomb?
Check out the introduction to building queries!
HEATMAP(duration_ms), or the statistical distribution of duration_ms, over the selected time period:
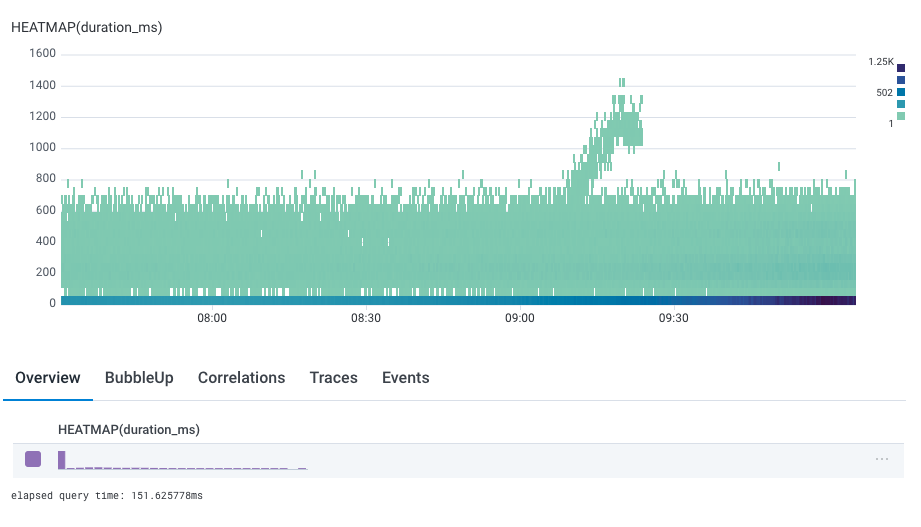
Create a Heatmap
To add a heatmap to a query:- In Query Builder, select the field within the SELECT clause.
- Enter
HEATMAPand the field you want visualized within parentheses. Alternatively, begin typingHEATMAPand select query components from the autocomplete prompts that Honeycomb provides. - Execute the query by selecting Run Query or pressing Shift + Enter on the keyboard.

When to Use
Heatmaps look best when you have a lot of events to visualize, and where the spread of values is wide enough to see some differentiation, but not complete noise. Any column representing a duration or size is a perfect fit, but any column you might run a percentile or average calculation on may benefit from being rendered as a heatmap as well.Interact with Heatmaps
The Rollover
The rollover for heatmaps shows a “bucket”, its range of values, and its count of events.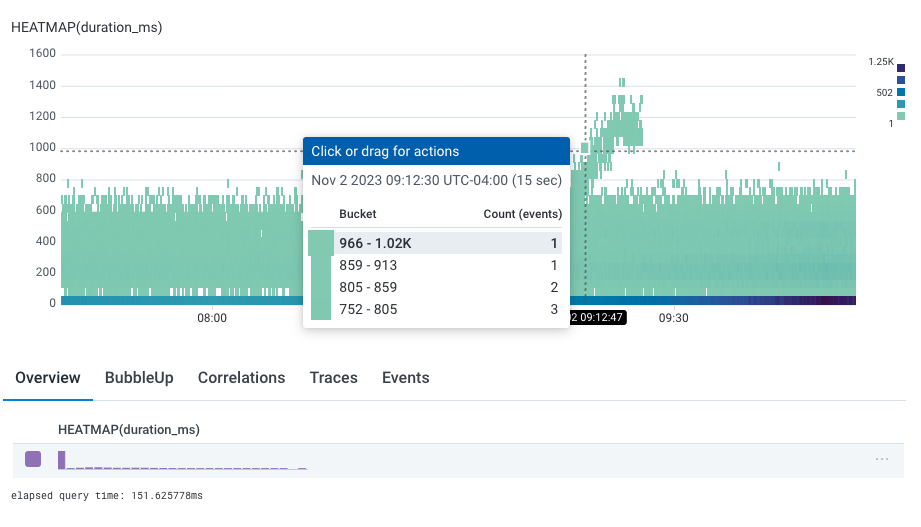
Use Heatmaps with Other Features
Group By
One of the most powerful features of Honeycomb is Query Builder’s GROUP BY clause, which groups results based on field values. Heatmaps work well with GROUP BY clauses. Take the query below, where we have grouped by status code, orapp.status_code.
By default, the heatmap of all status codes appears.
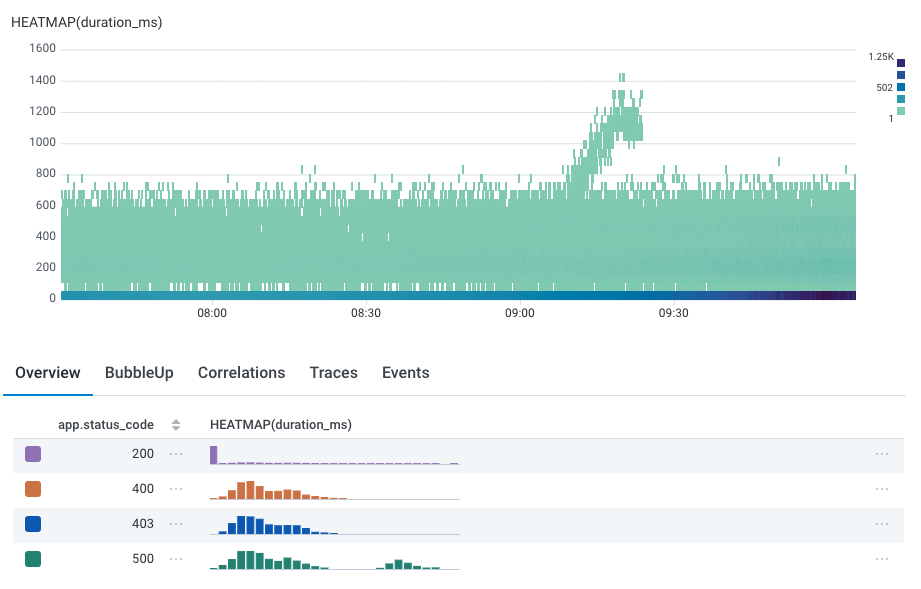
200 and 500 status codes are in the higher.
Just as we highlight the corresponding line in line graphs as you mouse over the summary table, we also show the heatmap corresponding to that group:

Tracing
For tracing-enabled datasets, selecting a cell in the histogram will choose an arbitrary trace that corresponds to the cell: that is, it has a span that fulfills theWHERE clause, started at that time, and has that value.
For example, if the user were to click in the group by image above, they would see a trace at 08:20 with a span of 1200 ms duration.