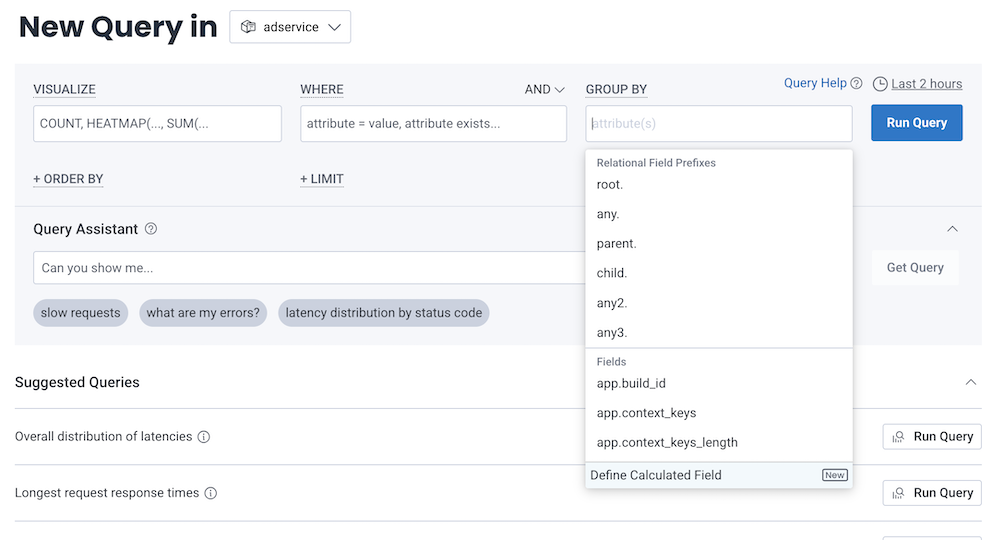
For clearer insights and consistency, use calculated fields to create new fields by applying functions and logic to existing data.
What is a Calculated Field?
Calculated fields (also called Derived Columns) let you create new data properties by applying functions, math, or logic to existing fields—similar to spreadsheet formulas.
Use Calculated Fields to:
- Simplify complex data to make event details more readable
- Track business measures that change over time
- Align disparate datasets
How Calculated Fields Work
In Honeycomb, Calculated Fields behave like any other field in your data and can be used in queries, boards, and alerts, depending on the scope.
If you have on-the-fly needs to combine or extract values from multiple columns, we’ve got you covered!
Honeycomb generates calculated fields at query-time, so you can run them on historical data.
Choosing the Scope
In Honeycomb, you can create calculated fields that are tied to a query session or save calculated fields for use across Honeycomb resources.
Calculated Fields Scoped to a Query
By default, calculated fields created through the Query Builder are scoped to your query, which means you can find the field again by name as long as you’re in the same query session.
This helps reduce dataset bloat and makes it easier to iterate quickly without needing to manage one-off or exploratory formulas long-term.
Use query-scoped calculated fields when you:
- Need a one-off calculation for an investigation or exploratory query
- Want to avoid cluttering your dataset with fields you’ll only use once
- Are iterating rapidly and don’t want to manage permanent schema changes
Saved Calculated Fields
You can also save calculated fields to either a specific dataset or an entire environment:
- When a calculation is relevant to only a specific dataset or service, use a dataset-specific calculated field.
- When a calculation needs to be shared across multiple datasets and services, use an environment-wide calculated field.
By default, Honeycomb shows environment calculated fields when building environment-wide queries and dataset calculated fields when building dataset queries.
Saved calculated fields can be used across Honeycomb resources, including in queries, Boards, and alerts.
Use Cases for Calculated Fields
To understand how you can use calculated fields in practical situations, explore these example scenarios.
Comparing Values
For advanced comparisons, calculated fields enable you to transform or categorize data dynamically, which not only simplifies data exploration but also ensures consistency in how comparisons are made across different investigations.
Standardizing Fields Across Multiple Datasets
Calculated fields let you standardize data across multiple datasets by defining consistent field names and expressions, which ensures queries return comparable results even when services implement fields differently.
This enables seamless cross-dataset analysis within an environment.
Creating Calculated Fields
You can create calculated fields in Honeycomb’s UI through:
- the Query Builder
- the Dataset’s schema for dataset-specific calculated fields
- the environment’s schema for environment-wide calculate fields
Query Builder
Dataset Schema
Environment Schema
-
Log in to the Honeycomb UI.
-
In the navigation menu, select Query.
-
From the New Query in dropdown, choose the dataset or environment you want to query.
-
Select either the SELECT, WHERE, or GROUP BY clause.
-
From the list of suggested fields, choose Create Calculated Field.
-
In the modal, enter details:
| Field | Description |
|---|
| Save toggle switch | Controls where the query is saved. Save to the query session only [off], or save to the selected dataset or environment [on]. |
| Display Name | Name that appears in the Query Builder. Enter a name that is unique across all datasets and the containing environment. Although Honeycomb tries to prevent duplicate field names, they can still occur. For help resolving naming conflicts, visit Common Issues with Queries: Calculated Fields. |
| Description | Description of your field. Use a maximum of 255 characters. |
| Prompt (beta) | Use natural language to generate a Calculated Field. For example, return "slow" if $duration_ms > 1000. Be sure to explicitly reference any schema fields using the syntax(forexample,‘field_name`). For help resolving errors, visit Common Issues with Queries: Calculated Fields. |
| Editor | Formula that defines your field. For syntax, available functions, and example formulas, visit Calculated Field Formula Reference. |
Hover over syntax errors (red underlines or red triangles) for suggestions on how to fix them.
-
Select Use in New Query.
Your calculated field may take up to one minute to appear.Saved calculated fields and query-scoped calculated fields in the SELECT clause will appear in dropdowns at the bottom of the field list.
Query-scoped calculated fields in the WHERE and GROUP BY clauses will appear in dropdowns under the In this query session section.To create a dataset-specific calculated field:
-
Log in to the Honeycomb UI.
-
In the navigation menu, select the Environment label, then choose the environment that includes the dataset to which you want to add a calculated field.
-
In the navigation menu, select Manage Data, then choose Datasets.
-
Locate the dataset to which you want to add a calculated field, and select its name to open its settings.
-
Go to the Schema view.
-
Expand the Calculated Fields section.
-
Select Add New Calculated Field.
-
In the modal, enter details:
| Field | Description |
|---|
| Display Name | Name that appears in the Query Builder. Enter a name that is unique across the dataset and its containing environment. Although Honeycomb tries to prevent duplicate field names, they can still occur. For help resolving naming conflicts, visit Common Issues with Queries: Calculated Fields. |
| Prompt (beta) | Use natural language to generate a Calculated Field. For example, return "slow" if $duration_ms > 1000. Be sure to explicitly reference any schema fields using the syntax(forexample,‘field_name`). For help resolving errors, visit Common Issues with Queries: Calculated Fields. |
| Editor | Formula that defines your field. For syntax, available functions, and example formulas, visit Calculated Field Formula Reference. |
Hover over syntax errors (red underlines or red triangles) for suggestions on how to fix them.
-
Select Save.
The screen refreshes, and your new field appears in the list. To create an environment-wide calculated field:
-
Log in to the Honeycomb UI.
-
In the navigation menu, select the Environment label, then choose Manage Environments.
-
Locate the environment to which you want to add a calculated field, and select its name to open its settings.
-
Go to the Schema view.
-
Select Add New Calculated Field.
-
In the modal, enter details:
| Field | Description |
|---|
| Display Name | Name that appears in the Query Builder. Enter a name that is unique across all datasets and the containing environment. Although Honeycomb tries to prevent duplicate field names, they can still occur. For help resolving naming conflicts, visit Common Issues with Queries: Calculated Fields. |
| Prompt (beta) | Use natural language to generate a Calculated Field. For example, return "slow" if $duration_ms > 1000. Be sure to explicitly reference any schema fields using the syntax(forexample,‘field_name`). For help resolving errors, visit Common Issues with Queries: Calculated Fields. |
| Editor | Formula that defines your field. For syntax, available functions, and example formulas, visit Calculated Field Formula Reference. |
Hover over syntax errors (red underlines or red triangles) for suggestions on how to fix them.
-
Select Save.
The screen refreshes, and your new field appears in the list. Managing Calculated Fields
Once created, edit query-scoped calculated fields in a clause by selecting their Edit icon ().
Saved calculated fields are part of the schema for a dataset or environment and must be managed within the settings for those areas.
To modify a saved calculated field, access the configuration associated with its scope:
Troubleshooting
For guidance when troubleshooting calculated fields in Honeycomb, visit Common Issues with Queries.