

Configuration
To send Fastly logs to Honeycomb, refer to the Fastly documentation.Sampling with VCL
Use Sampling to reduce data volume in your Honeycomb datasets where you are gathering Fastly data. To implement sampling, we recommend a configuration that uses:- A Logging rule, which only forwards logs for requests if they are included in the sampled data.
- Varnish Configuration Language (VCL) snippet(s), which determines if the request should be sampled and at what rate.
Configure Sampling
-
Update your Fastly configuration to create a logging rule, which forwards requests to Honeycomb only if the
req.http.log_requestlocal variable is set to"1".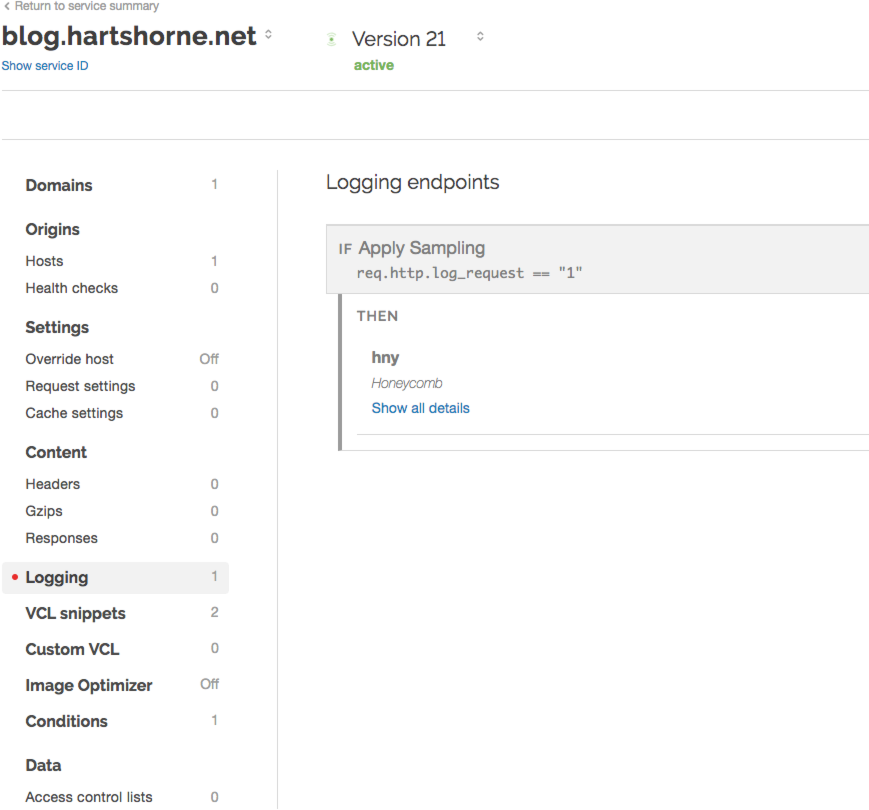
-
Create two VCL snippets:
-
A table of sample rates for status codes
For example, this table describes the number of events which flow through per sampled event based on status code.
1does not sample at all,20samples every 20th event, and so on. To use, copy and adjust the rates in this table based on your projection traffic: -
Code that sets the sample rate based on HTTP status
Use the following code to set the
req.http.log_requestvariable (as mentioned in the logging rule) if sampling should be applied: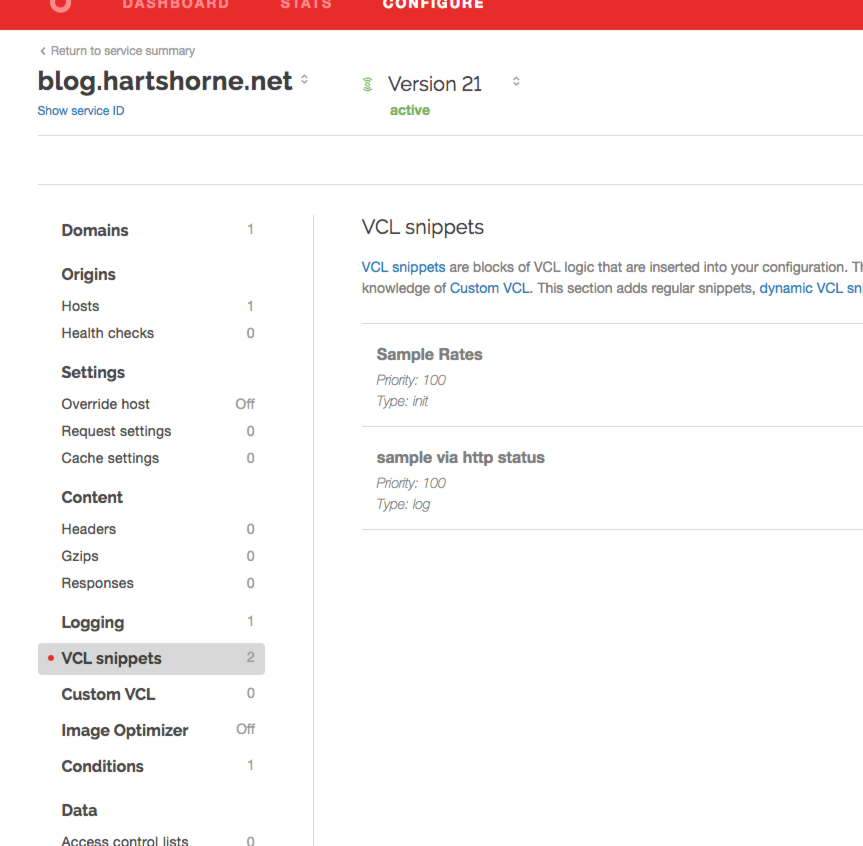
-
A table of sample rates for status codes
For example, this table describes the number of events which flow through per sampled event based on status code.
-
To ensure that the sample rate is included as a property of the JSON event and sent to Honeycomb, add this line at the same level of the
timeanddatakeys:This line encodessamplerateas a top0-level key sent to the Honeycomb API and causes all visualizations rendered by Honeycomb to appear as if all of the events, even ones which were sampled out, were sent.