

To add tracing to your Kubernetes cluster, refer to the OpenTelemetry Operator for Kubernetes.
Requirements
To use the Helm package, you will need Helm version 3 or better. You can still install the agent usingkubectl though configuration may be more involved.
You wil also need your Honeycomb API key.
Install using either Helm, or kubectl directly.
Getting Started Using Helm
To add tracing to your Kubernetes cluster, refer to the OpenTelemetry Operator for Kubernetes.
- kube-controller-manager
- kube-scheduler
-
Add the Honeycomb Helm repository.
-
Install the agent.
For more details about advanced configuration options, refer to the Helm chart.
Getting Started Using Kubectl
To add tracing to your Kubernetes cluster, refer to the OpenTelemetry Operator for Kubernetes.
-
Create a
honeycombnamespace. -
Store your Honeycomb API Key as a Kubernetes secret.
-
Add the agent to your cluster.
Logs Collection
The agent will collect logs based on configuredwatchers.
These watchers will match pods based on the configured selection and parse the logs for the pod using the specified parser.
The Helm chart exposes a watchers property that you can use.
If installed using kubectl, you will need to modify the watchers section of the ConfigMap.
Using modified log watchers configuration
A configuration to collect and parse logs from the Kubernetes controller manager and scheduler would look like this:Capturing events with Heptio Eventrouter
An optional configuration is to capture Kubernetes events using the Heptio Eventrouter component. Configure the Eventrouter to use thejson sink for logs, and you can capture them with this watchers configuration:
You will want to configure the agent to parse logs from your applications, but that depends a lot on your applications!
Read more about customizing the agent.
Metrics Collection
The agent collects metrics from nodes, pods, containers, and volumes. For each collection interval, an event for each resource will be sent to Honeycomb that contains all collected metrics as fields to the event. Kubernetes labels for the resources will be added as fields to the event with alabel. prefix.
Pods and containers also get additional status and restart metrics.
The default collection interval is every 10 seconds, for nodes and pods resources only.
Metrics List
Metrics collected depend on the Kubernetes resource type. You can filter metrics on thek8s.resource.type field.
| Metric | Node | Pod | Container | Volume |
|---|---|---|---|---|
metrics.cpu.usage | x | x | x | |
metrics.cpu.utilization | x | x | x | |
metrics.filesystem.available | x | x | x | |
metrics.filesystem.capacity | x | x | x | |
metrics.filesystem.usage | x | x | x | |
metrics.memory.available | x | x | x | |
metrics.memory.major_page_faults | x | x | x | |
metrics.memory.page_faults | x | x | x | |
metrics.memory.rss | x | x | x | |
metrics.memory.usage | x | x | x | |
metrics.memory.utilization | x | x | x | |
metrics.memory.working_set | x | x | x | |
metrics.network.bytes.receive | x | x | ||
metrics.network.bytes.send | x | x | ||
metrics.network.errors.receive | x | x | ||
metrics.network.errors.send | x | x | ||
metrics.uptime | x | x | x | |
metrics.volume.available | x | |||
metrics.volume.capacity | x | |||
metrics.volume.inodes.free | x | |||
metrics.volume.inodes.total | x | |||
metrics.volume.inodes.used | x | |||
metrics.volume.used | x | |||
status.exitcode | x | |||
status.message | x | x | ||
status.phase | x | |||
status.ready | x | |||
status.reason | x | x | ||
status.restart | x | x | ||
status.restart_count | x | x | ||
status.restart_delta | x | x | ||
status.state | x |
How the Honeycomb Kubernetes Agent Works
The Honeycomb Kubernetes Agent runs as a DaemonSet. That is, one copy of the agent runs on each node in the cluster.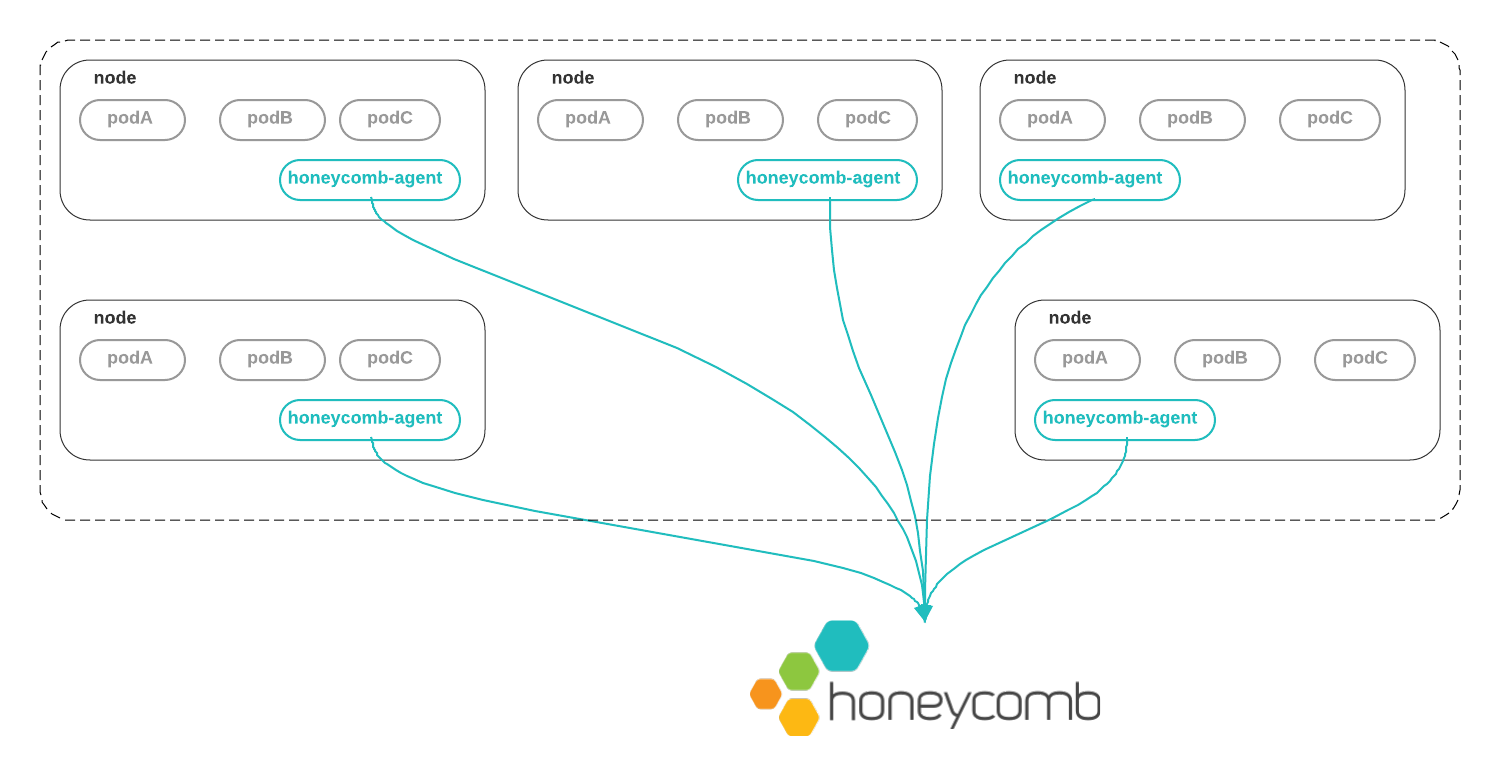
stdout and stderr are written by the Docker daemon to the local node filesystem.
The Honeycomb Kubernetes Agent reads these logs, augments them with metadata from the Kubernetes API, and ships them to Honeycomb so that you can observe what is going on.
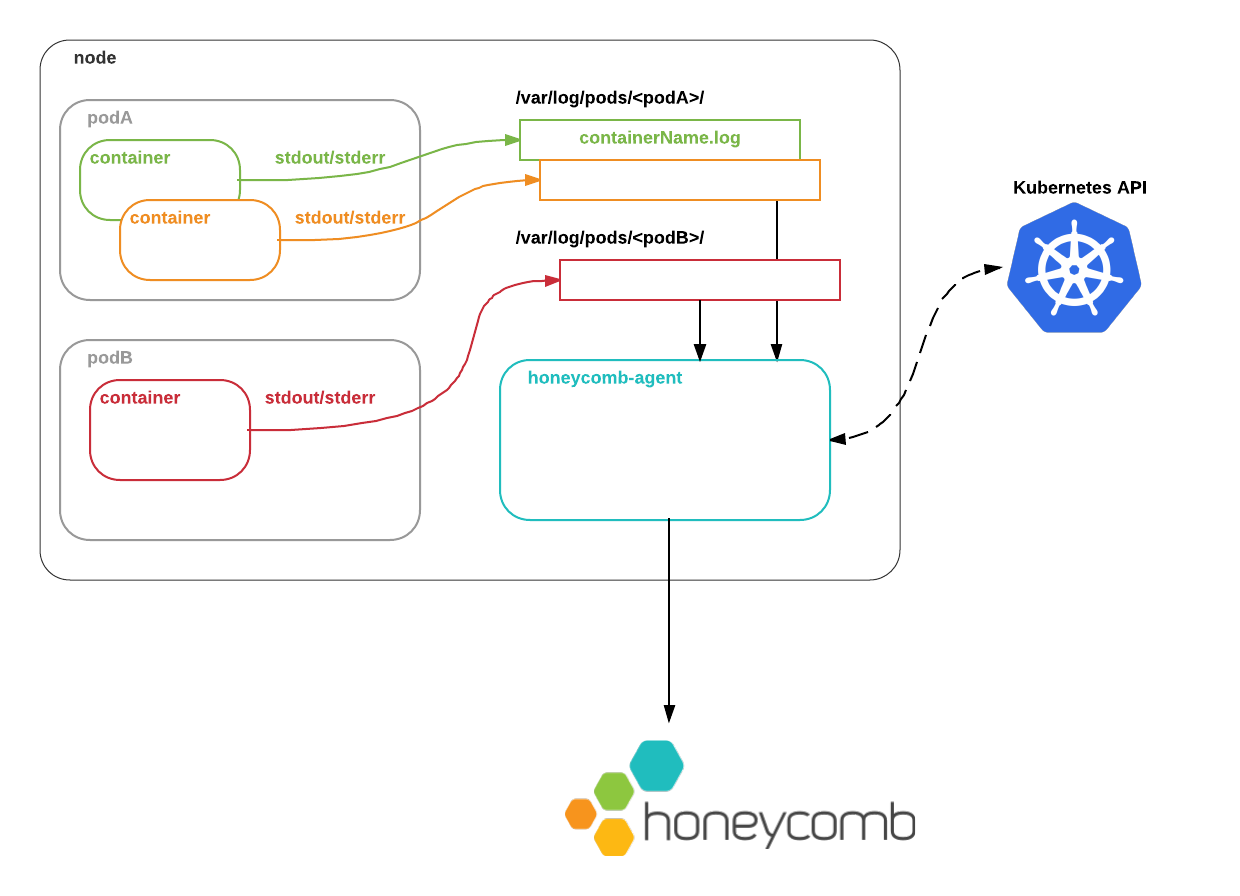
Metadata
What metadata does the agent add to these logs?pod.labelspod.namepod.namespacepod.resourceVersionpod.UIDpod.nodeNamepod.nodeSelectorpod.serviceAccountNamepod.subdomainpod.annotationscontainer.argscontainer.commandcontainer.namecontainer.envcontainer.imagecontainer.portscontainer.VolumeMountscontainer.workingDircontainer.resources
includeNodeLabels: true within the agent’s metrics configuration.
Modifying Configuration
You can modify the agent’s configuration via theConfigMap deployed.
By default, Kubernetes resource metrics and logs from the controller and scheduler will be collected.
Applications in Kubernetes tend to use different logging formats.
In our opinion, your own applications should use a structured, self-describing log format such as JSON.
But Kubernetes system components use the glog format, reverse proxies and ingress controllers may use a combined log format, and so on.
You might also want to aggregate events only from specific services, rather than from everything that might be running in a cluster.
Or you might want to send logs from different services to different datasets.
To accommodate these real-world use cases, you can customize the Honeycomb Kubernetes Agent’s behavior with a YAML configuration file.
Ordinarily, you will create this file as a Kubernetes ConfigMap that will be mounted inside the agent container.
Metrics Collection Configuration
Metrics collection can be configured using themetrics configuration property.
clusterName must be specified for each cluster.
By default, only node and pod metrics will be collected.
The following table describes all properties for metrics configuration:
| Key | Required? | Type | Description |
|---|---|---|---|
enabled | yes | bool | Enables metrics to be collected and sent to Honeycomb. default: false |
dataset | yes | string | Name of dataset to sent events to. default: kubernetes-metrics |
clusterName | yes | string | Name of Kubernetes cluster. Will be emitted as a field to Honeycomb. default: k8s-cluster |
interval | no | string | Collection interval in time duration format, which is specified with a duration suffix. Valid time units are ns, us (or µs), ms, s, m, h. default: 10s |
metricGroups | no | list | Resource groups to collected metrics from. Valid values are: node, pod, container, volume. default: node, pod |
omitLabels | no | list | Labels in this list will not be collected and sent as fields to Honeycomb. default: nil |
additionalFields | no | map | A map of fields name and values to apply to each metric event. default: nil |
includeNodeLabels | no | bool | If enabled, attaches node metadata to metric events. Node labels will respect the omitLabels list. |
Example Metrics Configuration
This configuration will collect metrics from the node, pods, containers, and volumes, every 10 seconds. The auto generatedcontroller-revision-hash label will be omitted, and additional fields for region and az will be added.
Log Watchers Configuration
Logs parsing and collection can be configured using thewatchers configuration property.
watchers list describes a set of pods whose logs you want to handle in a specific way, and has the following keys:
| Key | Required? | Type | Description |
|---|---|---|---|
labelSelector | yes* | string | A Kubernetes label selector identifying the set of pods to watch. |
parser | yes | string | Describes how this watcher should parse events. |
dataset | yes | string | The dataset that this watcher should send events to. |
containerName | no | string | If you only want to consume logs from one container in a multi-container pod, the name of the container to watch. |
processors | no | list | A list of processors to apply to events after they are parsed. |
namespace | no | string | The Kubernetes namespace the pods are located in. If not supplied, default namespace is used. |
paths | no | string array | Glob-style* paths to the log files. If not supplied, the default Kubernetes log paths and filenames are used. |
exclude | no | string array | Glob-style* paths for files to exclude from consideration. If a given file matches an exclude, it will not be watched. If not supplied, no files are excluded. |
*matches any sequence of non-path-separators./**/matches zero or more directories.?matches any single non-path-separator character.
Validating a Configuration File
To check a configuration file without needing to deploy it into the cluster, you can run the Honeycomb Kubernetes Agent container locally with the--validate flag:
Uploading a Configuration File to a Cluster
To make a configuration file visible to the Honeycomb Kubernetes Agent inside a Kubernetes cluster, you will need to create a KubernetesConfigMap from it.
To create a brand-new ConfigMap from a local file config.yaml, run:
ConfigMap, you can run:
Parsers
Currently, the following parsers are supported:Nop
Does no parsing on logs, and submits an event with the entire contents of the log line in a"log" field, plus the aforementioned kubernetes metadata.
Use this if you just want the “raw” log line, or if your log line structure does not match one of the parsers below.
You can still query datasets with raw log lines to some degree using string filters and calculated fields, but structuring your logs is strongly encouraged.
JSON
JSON is a great format for structured logs. With the JSON parser, we map JSON key/value pairs to event fields.NGINX
Parses NGINX access logs. If you are using a custom NGINX log format, you can specify the format using the following configuration:This uses the enhanced additional log fields from our using NGINX with Honeytail guide.
You may need to modify the log format in the watcher YAML, or your NGINX config file / ConfigMap, to match.
Glog
Parses logs produced by glog, which look like this:Redis
Parses logs produced by redis 3.0+, which look like this:Keyval
Parses logs inkey=value format, such as:
=, then it will be interpreted as a key without a value.
For example, if a log contains text:
keyval parser will create an event that looks similar to:
keyval parser, extra care should be taken when using it.
Processors
Processors transform events after they are parsed. Currently, the following processors are supported:additional_fields
Theadditional_fields processor accepts a static map of field names and values and appends those to every event it processes.
These values will overwrite existing fields of the same name, if they exist.
For example, with the following configuration:
sample
Thesample processor will only send a subset of events to Honeycomb.
Honeycomb natively supports sampled event streams, allowing you to send a representative subset of events while still getting high-fidelity query results.
Options:
| Key | Type | Description |
|---|---|---|
type | "static" or "dynamic" | How events should be sampled. |
rate | integer | The rate at which to sample events. Specifying a sample rate of 20 will cause one in 20 events to be sent. |
keys | list of strings | The list of field keys to use when doing dynamic sampling. |
windowsize | integer | How often to refresh estimated sample rates during dynamic sampling, in seconds. Default: 30s. |
minEventsPerSec | integer | Whenever the number of events per second being processed falls below this value for a time window (see windowSize), sampling will be disabled for the next time window (all events will be sent with a sample rate of 1). Default: 50. The minimum possible value is 1. |
drop_field
Thedrop_field processor will remove the specified field from all events before sending them to Honeycomb.
This is useful for removing sensitive information from events.
Options:
| Key | Value | Description |
|---|---|---|
field | string | The name of the field to drop. |
request_shape
Therequest_shape processor will take a field representing an HTTP request, such as GET /api/v1/users?id=22 HTTP/1.1, and unpack it into its constituent parts.
Options:
| Key | Value | Description |
|---|---|---|
field | string | The name of the field containing the HTTP request (for example, "request") |
patterns | list of strings | A list of URL patterns to match when unpacking the request |
queryKeys | list of strings | An allowlist of keys in the URL query string to unpack |
prefix | string | A prefix to prepend to the unpacked field names |
timefield
Thetimefield processor will replace the default timestamp in an event with one extracted from a specific field in the event.
Options:
| Key | Value | Description |
|---|---|---|
field | string | The name of the field containing the timestamp |
format | string | The format of the timestamp found in timefield, in strftime or Golang format |
This processor is not generally necessary when collecting pod logs.
The Honeycomb Kubernetes Agent will automatically use the timestamp recorded by the Docker json-log driver.
It is useful when parsing logs that live at a particular path on the node filesystem, such as Kubernetes audit logs.
Sample Configurations
Here are some example Kubernetes Honeycomb Agent configurations. Parse logs from pods labelled withapp: nginx:
sidecar container: